

Bevy 0.12
Posted on November 4, 2023 by Bevy Contributors

Thanks to 185 contributors, 567 pull requests, community reviewers, and our generous sponsors, we're happy to announce the Bevy 0.12 release on crates.io!
For those who don't know, Bevy is a refreshingly simple data-driven game engine built in Rust. You can check out our Quick Start Guide to try it today. It's free and open source forever! You can grab the full source code on GitHub. Check out Bevy Assets for a collection of community-developed plugins, games, and learning resources.
To update an existing Bevy App or Plugin to Bevy 0.12, check out our 0.11 to 0.12 Migration Guide.
Since our last release a few months ago we've added a ton of new features, bug fixes, and quality of life tweaks, but here are some of the highlights:
- Deferred Rendering: (Optional) support for rendering in a Deferred style, which complements Bevy's existing Forward+ renderer by adding support for new effects and different performance tradeoffs. Bevy is now a "hybrid" renderer, meaning you can use both at the same time!
- Bevy Asset V2: A brand new asset system that adds support for asset preprocessing, asset configuration (via .meta files), multiple asset sources, recursive dependency load tracking, and more!
- PCF Shadow Filtering: Bevy now has smoother shadows thanks to Percentage-Closer Filtering.
- StandardMaterial Light Transmission: Bevy's PBR material now supports light transmission, making it possible to simulate materials like glass, water, plastic, foliage, paper, wax, marble, etc.
- Material Extensions: Materials can now build on other materials. You can now easily write shaders that build on existing materials, such as Bevy's PBR StandardMaterial.
- Rusty Shader Imports: Bevy's granular shader import system now uses Rust-style imports, expanding the capabilities and usability of the import system.
- Suspend and Resume on Android: Bevy now supports suspend and resume events on Android, which was the last big missing piece in our Android story. Bevy now supports Android!
- Automatic Batching and Instancing of Draw Commands: Draw commands are now automatically batched / instanced when possible, yielding significant render performance wins.
- Renderer Optimizations: Bevy's renderer dataflow has been reworked to squeeze out more performance and prepare the way for future GPU-driven rendering.
- One Shot Systems: ECS Systems can now be run on-demand from other systems!
- UI Materials: Add custom material shaders to Bevy UI nodes.
Deferred Rendering #
The two most popular "rendering styles" are:
- Forward Rendering: do all material/lighting calculations in a single render pass
- Pros: Simpler to work with. Works on / performs better on more hardware. Supports MSAA. Handles transparency nicely.
- Cons: Lighting is more expensive / fewer lights supported in a scene, some rendering effects are impossible (or harder) without a prepass
- Deferred Rendering: do one or more pre-passes that collect relevant information about a scene, then do material/lighting calculations in screen space in a final pass after that.
- Pros: Enables some rendering effects that are not possible in forward rendering. This is especially important for GI techniques, cuts down on shading cost by only shading visible fragments, can support more lights in a scene
- Cons: More complicated to work with. Requires doing prepasses, which can be more expensive than an equivalent forward renderer in some situations (although the reverse can also be true), uses more texture bandwidth (which can be prohibitive on some devices), doesn't support MSAA, transparency is harder / less straightforward.
Bevy's renderer has historically been a "forward renderer". More specifically, it is a Clustered Forward / Forward+ renderer, which means we break the view frustum up into clusters and assign lights to those clusters, allowing us to render many more lights than a traditional forward renderer.
However, as Bevy has grown, it has slowly moved into "hybrid renderer" territory. In previous releases, we added a Depth and Normal Prepass to enable TAA, SSAO, and Alpha Texture Shadow Maps. We also added a Motion Vector Prepass to enable TAA.
In Bevy 0.12 we added optional support for Deferred Rendering (building on the existing prepass work). Each material can choose whether it will go through the forward or deferred path, and this can be configured per-material-instance. Bevy also has a new DefaultOpaqueRendererMethod resource, which configures the global default. This is set to "forward" by default. The global default can be overridden per-material.
Lets break down the components of this deferred render:

When deferred is enabled for the PBR StandardMaterial, the deferred prepass packs PBR information into the Gbuffer, which can be broken up into:
Base Color 
Depth 
Normals 
Perceptual Roughness 
Metallic 
The deferred prepass also produces a "deferred lighting pass ID" texture, which determines what lighting shader to run for the fragment:

These are passed into the final deferred lighting shader.
Note that the cube in front of the flight helmet model and the ground plane are using forward rendering, which is why they are black in both of the deferred lighting textures above. This illustrates that you can use both forward and deferred materials in the same scene!
Note that for most use cases, we recommend using forward by default, unless a feature explicitly needs deferred or your rendering conditions benefit from deferred style. Forward has the fewest surprises and will work better on more devices.
PCF Shadow Filtering #
Shadow aliasing is a very common problem in 3D apps:

Those "jagged lines" in the shadow are the result of the shadow map being "too small" to accurately represent the shadow from this perspective. The shadow map above is stored in a 512x512 texture, which is a lower resolution than most people will use for most of their shadows. This was selected to show a "bad" case of jaggies. Note that Bevy defaults to 2048x2048 shadowmaps.
One "solution" is to bump up the resolution. Here is what it looks like with a 4096x4096 shadow map.

Looking better! However this still isn't a perfect solution. Large shadowmaps aren't feasible on all hardware. They are significantly more expensive. And even if you can afford super high resolution shadows, you can still encounter this issue if you place an object in the wrong place, or point your light in the wrong direction. You can use Bevy's Cascaded Shadow Maps (which are enabled by default) to cover a larger area, with higher detail close to the camera and less detail farther away. However even under these conditions, you will still probably encounter these aliasing issues.
Bevy 0.12 introduces PCF Shadow Filtering (Percentage-Closer Filtering), which is a popular technique that takes multiple samples from the shadow map and compares with an interpolated mesh surface depth-projected into the frame of reference of the light. It then calculates the percentage of samples in the depth buffer that are closer to the light than the mesh surface. In short, this creates a "blur" effect that improves shadow quality, which is especially evident when a given shadow doesn't have enough "shadow map detail". Note that PCF is currently only supported for DirectionalLight and SpotLight.
Bevy 0.12's default PCF approach is the ShadowMapFilter::Castano13 method by Ignacio Castaño (used in The Witness). Here it is with a 512x512 shadow map:
Drag this image to compare


Much better!
We also implemented the ShadowMapFilter::Jimenez14 method by Jorge Jimenez (used in Call of Duty Advanced Warfare). This can be slightly cheaper than Castano, but it can flicker. It benefits from Temporal Anti-Aliasing (TAA) which can reduce the flickering. It can also blend shadow cascades a bit more smoothly than Castano.
Drag this image to compare

StandardMaterial Light Transmission #
The StandardMaterial now supports a number of light transmission-related properties:
specular_transmissiondiffuse_transmissionthicknessiorattenuation_colorattenuation_distance
These allow you to more realistically represent a wide variety of physical materials, including clear and frosted glass, water, plastic, foliage, paper, wax, marble, porcelain and more.
Diffuse transmission is an inexpensive addition to the PBR lighting model, while specular transmission is a somewhat more resource-intensive screen-space effect, that can accurately model refraction and blur effects.

To complement the new transmission properties, a new TransmittedShadowReceiver component has been introduced, which can be added to entities with diffuse transmissive materials to receive shadows cast from the opposite side of the mesh. This is most useful for rendering thin, two-sided translucent objects like tree leaves or paper.
Additionally, two extra fields have been added to the Camera3d component: screen_space_specular_transmission_quality and screen_space_specular_transmission_steps. These are used to control the quality of the screen-space specular transmission effect (number of taps), and how many “layers of transparency” are supported when multiple transmissive objects are in front of each other.
Important: Each additional “layer of transparency” incurs in a texture copy behind the scenes, adding to the bandwidth cost, so it's recommended to keep this value as low as possible.
Finally, importer support for the following glTF extensions has been added:
KHR_materials_transmissionKHR_materials_iorKHR_materials_volume
Check out this video to see it in action!
Compatibility #
Both specular and diffuse transmission are compatible with all supported platforms, including mobile and Web.
The optional pbr_transmission_textures Cargo feature allows using textures to modulate the specular_transmission, diffuse_transmission and thickness properties. It's disabled by default in order to reduce the number of texture bindings used by the standard material. (These are severely constrained on lower-end platforms and older GPUs!)
DepthPrepass and TAA can greatly improve the quality of the screen-space specular transmission effect, and are recommended to be used with it, on the platforms where they are supported.
Implementation Details #
Specular transmission is implemented via a new Transmissive3d screen space refraction phase, which joins the existing Opaque3d, AlphaMask3d and Transparent3d phases. During this phase, one or more snapshots of the main texture are taken, which are used as “backgrounds” for the refraction effects.
Each fragment's surface normal and IOR (index of refraction) used along with the view direction to calculate a refracted ray. (Via Snell's law.) This ray is then propagated through the mesh's volume (by a distance controlled by the thickness property), producing an exit point. The “background” texture is then sampled at that point. Perceptual roughness is used along with interleaved gradient noise and multiple spiral taps, to produce a blur effect.
Diffuse transmission is implemented via a second, reversed and displaced fully-diffuse Lambertian lobe, which is added to the existing PBR lighting calculations. This is a simple and relatively cheap approximation, but works reasonably well.
Bevy Asset V2 #
Asset pipelines are a central part of the gamedev process. Bevy's old asset system was suitable for some classes of app, but it had a number of limitations that prevented it from serving the needs of other classes, especially higher end 3D apps.
Bevy Asset V2 is a completely new asset system that learns from the best parts of Bevy Asset V1 while adding support for a number of important scenarios: Asset Importing/Preprocessing, Asset Meta Files, Multiple Asset Sources, Recursive Asset Dependency Load Events, Async Asset I/O, Faster and More Featureful Asset Handles, and more!
Most existing user-facing asset code will either require no changes at all, or minimal changes. Custom AssetLoader or AssetReader code will need to change slightly, but generally the changes should be very minimal. Bevy Asset V2 (despite being a completely new implementation) largely just expands what Bevy is capable of.
Asset Preprocessing #

Asset preprocessing is the ability to take an input asset of a given type, process it in some way (generally during development time), and then use the result as the final asset in your application. Think of it as an "asset compiler".
This enables a number of scenarios:
- Reduce Work In Released Apps: Many assets aren't composed in their ideal form for release. Scenes might be defined in a human-readable text format that is slower to load. Images might be defined in formats that require more work to decode and upload to the GPU, or take up more space on the GPU when compared to GPU-friendly formats (ex: PNG images vs Basis Universal). Preprocessing enables developers to convert to release-optimal formats ahead of time, making apps start up faster, take up fewer resources, and perform better. It also enables moving computation work that would have been done at runtime to development time. For example, generating mipmaps for images.
- Compression: Minimize the disk space and/or bandwidth that an asset takes up in deployed apps
- Transformation: Some "asset source files" aren't in the right format by default. You can have an asset of type
Aand transform it into typeB.
If you are building an app that tests the limits of your hardware with optimal formats ... or you just want to cut down on startup / loading times, asset preprocessing is for you.
For an in-depth technical breakdown of the implementation we chose, check out the Bevy Asset V2 pull request.
Enabling Pre-Processing #
To enable asset pre-processing, just configure your AssetPlugin like this:
app.add_plugins
This will configure the asset system to look for assets in the imported_assets folder instead of the assets "source folder". During development, enable the asset_processor cargo feature flag like this:
This will start the AssetProcessor in parallel with your app. It will run until all assets are read from their source (defaults to the assets folder), processed, and the results have been written to their destination (defaults to the imported_assets folder). This pairs with asset hot-reloading. If you make a change, this will be detected by the AssetProcessor, the asset will be reprocessed, and the result will be hot-reloaded in your app.
Should You Enable Pre-Processing Today? #
In future Bevy releases we will recommended enabling processing for the majority of apps. We don't yet recommend it for most use cases for a few reasons:
- Most of our built-in assets don't have processors implemented for them yet. The
CompressedImageSaveris the only built-in processor and it has a bare-minimum set of features. - We have not implemented "asset migrations" yet. Whenever an asset changes its settings format (which is used in meta files), we need to be able to automatically migrate existing asset meta files to the new version.
- As people adopt processing, we expect some flux as we respond to feedback.
Incremental and Dependency Aware #
Bevy Asset V2 will only process assets that have changed. To accomplish this, it computes and stores hashes of each asset source file:
hash: ,
It also tracks the asset dependencies used when processing an asset. If a dependency has changed, the dependant asset will also be re-processed!
Transactional and Reliable #
Bevy Asset V2 uses write-ahead logging (a technique commonly used by databases) to recover from crashes / forced exists. Whenever possible it avoids full-reprocessing and only reprocesses incomplete transactions.
The AssetProcessor can close (either intentionally or unintentionally) at any point in time and it will pick up right where it left off!
If a Bevy App asks to load an asset that is currently being processed (or re-processed), the load will asynchronously wait until both the processed asset and its meta file have been written. This ensures that a loaded asset file and meta file always "match" for a given load.
Asset Meta Files #
Assets now support (optional) .meta files. This enables configuring things like:
- The asset "action"
- This configures how Bevy's asset system should handle the asset:
Load: Load the asset without processingProcess: Pre-process the asset prior to loadingIgnore: Do not process or load the asset
- This configures how Bevy's asset system should handle the asset:
AssetLoadersettings- You can use meta files to set any
AssetLoaderyou want - Configure loader settings like "how to filter an image", "adjusting the up axis in 3D scenes", etc
- You can use meta files to set any
Processsettings (if using theProcessaction)- You can use meta files to set any
Processimplementation you want - Configure processor settings like "what type of compression to use", "whether or not to generate mipmaps", etc
- You can use meta files to set any
A meta file for an unprocessed image looks like this:
A meta file for an image configured to be processed looks like this:
If the asset processor is enabled, meta files will be automatically generated for assets.
The final "output" metadata for the processed image looks like this:
This is what is written to the imported_assets folder.
Note that the Process asset mode has changed to Load. This is because in the released app, we will load the final processed image "normally" like any other image asset. Note that in this case, the input and the output asset both use ImageLoader. However the processed asset can use a different loader if the context demands it. Also note the addition of the processed_info metadata, which is used to determine if an asset needs to be reprocessed.
The final processed asset and metadata files can be viewed and interacted with like any other file. However they are intended to be read-only. Configuration should happen on the source asset, not the final processed asset.
CompressedImageSaver #

Bevy 0.12 ships with a barebones CompressedImageSaver that writes images to Basis Universal (a GPU-friendly image interchange format) and generates mipmaps. Mipmaps reduce aliasing artifacts when sampling images from different distances. This fills an important gap, as Bevy previously had no way to generate mipmaps on its own (it relied on external tooling). This can be enabled with the basis-universal cargo feature.
Preprocessing is Optional! #
Despite eventually (in future Bevy releases) recommending that most people enable asset processing, we also acknowledge that Bevy is used in a variety of applications. Asset processing introduces additional complexity and workflow changes that some people will not want!
This is why Bevy offers two asset modes:
AssetMode::Unprocessed: Assets will be loaded directly from the asset source folder (defaults toassets) without any preprocessing. They are assumed to be in their "final format". This is the mode/workflow Bevy users are currently used to.AssetMode::Processed: Assets will be pre-processed at development time. They will be read from their source folder (defaults toassets) and then written to their destination folder (defaults toimported_assets).
To enable this, Bevy uses a novel approach to assets: the difference between a processed and unprocessed asset is perspective. They both use the same .meta format and they use the same AssetLoader interface.
A Process implementation can be defined using arbitrary logic, but we heavily encourage using the LoadAndSave Process implementation. LoadAndSave takes any AssetLoader and passes the results to an AssetSaver.
That means if you already have an ImageLoader, which loads images, all you need to do is write some ImageSaver which will write the image in some optimized format. This both saves development work and makes it easy to support both processed and unprocessed scenarios.
Built To Run Anywhere #
Unlike many other asset processors in the gamedev space, Bevy Asset V2's AssetProcessor is intentionally architected to run on any platform. It doesn't use platform-limited databases or require the ability/permission to run a networked server. It can be deployed alongside a released app if your application logic requires processing at runtime.
One notable exception: we still need to make a few changes before it can run on the web, but it was built with web support in mind.
Recursive Asset Dependency Load Events #
The AssetEvent enum now has an AssetEvent::LoadedWithDependencies variant. This is emitted when an Asset, its dependencies, and all descendant / recursive dependencies have loaded.
This makes it easy to wait until an Asset is "fully loaded" before doing something.
Multiple Asset Sources #
It is now possible to register more than one AssetSource (which replaces the old monolithic "asset provider" system).
Loading from the "default" AssetSource looks exactly like it does in previous Bevy versions:
sprite.texture = assets.load;
But in Bevy 0.12 you can now register named AssetSource entries. For example you could register a remote AssetSource that loads assets from an HTTP server:
sprite.texture = assets.load;
Features like hot-reloading, meta files, and asset processing are supported across all sources.
You can register a new AssetSource like this:
// reads assets from the "other" folder, rather than the default "assets" folder
app.register_asset_source
)
Embedded Assets #
One of the features motivating Multiple Asset Sources was improving our "embedded-in-binary" asset loading. The old load_internal_asset! approach had a number of issues (see the relevant section in this PR).
The old system looked like this:
pub const MESH_SHADER_HANDLE: = weak_from_u128;
load_internal_asset!;
This required a lot of boilerplate and didn't integrate cleanly with the rest of the asset system. The AssetServer was not aware of these assets, hot-reloading required a special-cased second AssetServer, and you couldn't load assets using an AssetLoader (they had to be constructed in memory). Not ideal!
To prove out the Multiple Asset Sources implementation, we built a new embedded AssetSource, which replaces the old load_internal_asset! system with something that naturally fits into the asset system:
// Called in `crates/bevy_pbr/src/render/mesh.rs`
embedded_asset!;
// later in the app
let shader: = asset_server.load;
That is a lot less boilerplate than the old approach!
And because the embedded source is just like any other asset source, it can support hot-reloading cleanly ... unlike the old system. To hot-reload assets embedded in the binary (ex: to get live updates on a shader you have embedded in the binary), just enable the new embedded_watcher cargo feature.
Much better!
Extendable #
Almost everything in Bevy Asset V2 can be extended with trait impls:
Asset: Define new asset typesAssetReader: Define customAssetSourceread logicAssetWriter: Define customAssetSourcewrite logicAssetWatcher: Define customAssetSourcewatching / hot-reloading logicAssetLoader: Define custom load logic for a givenAssettypeAssetSaver: Define custom save logic for a givenAssettypeProcess: Define fully bespoke processor logic (or use the more opinionatedLoadAndSaveProcessimpl)
Async Asset I/O #
The new AssetReader and AssetWriter APIs are async! This means naturally async backends (like networked APIs) can directly call await on futures.
The filesystem impls (such as FileAssetReader) offload file IO to a separate thread and the future resolves when the file operation has finished.
Improved Hot-Reloading Workflow #
Previous versions of Bevy required manually enabling asset hot-reloading in your app code (in addition to enabling the filesystem_watcher cargo feature):
// Enabling hot reloading in old versions of Bevy
app.add_plugins
This was suboptimal because released versions of apps generally don't want filesystem watching enabled.
In Bevy 0.12 we've improved this workflow by making the new file_watcher cargo feature enable file watching in your app by default. During development, just run your app with the feature enabled:
When releasing, just omit that feature. No code changes required!
Better Asset Handles #
Asset handles now use a single Arc at their core to manage the lifetime of an asset. This simplifies the internals significantly and also enables us to make more asset information available directly from handles.
Notably, in Bevy 0.12 we use this to provide direct AssetPath access from the Handle:
// Previous version of Bevy
let path = asset_server.get_handle_path;
// Bevy 0.12
let path = handle.path;
Handles now also use a smaller / cheaper-to-look-up AssetIndex internally, which uses generational indices to look up assets in dense storage.
True Copy-on-Write Asset Paths #
The AssetServer and AssetProcessor do a lot of AssetPath cloning (across many threads). In previous versions of Bevy, AssetPath was backed by Rust's Cow type. However in Rust, cloning an "owned" Cow results in a clone of the internal value. This is not the "clone on write" behavior we want for AssetPath. We use AssetPath across threads, so we need to start with an "owned" value.
To prevent all of this cloning and re-allocating of strings, we've built our own CowArc type, which AssetPath uses internally. It has two tricks up its sleeve:
- The "owned" variant is an
Arc<str>, which we can cheaply clone without reallocating the string. - Almost all
AssetPathvalues defined in code come from a&'static str. We've created a specialCowArc::Staticvariant that retains this static-ness, meaning we do zero allocations even when turning a borrow into an "ownedAssetPath".
Suspend and Resume on Android #
On Android, applications no longer crash on suspend. Instead, they are paused, and no systems will run until the application is resumed.
This resolves the last "big" showstopper for Android apps! Bevy now supports Android!
Background tasks working in other threads, like playing audio, won't be stopped. When the application will be suspended, a Lifetime event ApplicationLifetime::Suspended is sent, corresponding to the onStop() callback. You should take care to pause tasks that shouldn't run in the background, and resume them when receiving the ApplicationLifetime::Resumed event (corresponding to the onRestart() callback).
Material Extensions #
Bevy has a powerful shader import system, allowing modular (and granular) shader code reuse. In previous versions of Bevy, this meant that in theory, you could import Bevy's PBR shader logic and use it in your own shaders. However in practice this was challenging, as you had to re-wire everything up yourself, which required intimate knowledge of the base material. For complicated materials like Bevy's PBR StandardMaterial, this was full of boilerplate, resulted in code duplication, and was prone to errors.
In Bevy 0.12, we've built a Material Extensions system, which enables defining new materials that build on existing materials:

This is accomplished via a new ExtendedMaterial type:
app.add_plugin;
let material = ;
We also paired this with some StandardMaterial shader refactors to make it much easier to pick and choose which parts you want:
// quantized_material.wgsl
@group @binding
my_extended_material: QuantizedMaterial;
@fragment
This vastly simplifies writing custom PBR materials, making it accessible to pretty much everyone!
Automatic Batching and Instancing of Draw Commands #
Bevy 0.12 now automatically batches/instances draw commands where possible. This cuts down the number of draw calls, which yields significant performance wins!
This required a number of architectural changes, including how we store and access per-entity mesh data (more on this later).
Here are some benches of the old unbatched approach (0.11) to the new batched approach (0.12):
2D Mesh Bevymark (frames per second, more is better) #
This renders 160,000 entities with textured quad meshes (160 groups of 1,000 entities each, each group sharing a material). This means we can batch each group, resulting in only 160 instanced draw calls when batching is enabled. This gives a 200% increase in frame rate (3x)!

3D Mesh "Many Cubes" (frames per second, more is better) #
This renders 160,000 cubes, of which ~11,700 are visible in the view. These are drawn using a single instanced draw of all visible cubes which enables up to 100% increase in frame rate (2x)!

These performance benefits can be leveraged on all platforms, including WebGL2!
What can be batched? #
Batching/Instancing can only happen for GPU data that doesn't require "rebinding" (binding is making data available to shaders / pipelines, which incurs a runtime cost). This means if something like a pipeline (shaders), bind group (shader-accessible bound data), vertex / index buffer (mesh) is different, it cannot be batched.
From a high level, currently entities with the same material and mesh can be batched.
We are investigating ways to make more data accessible without rebinds, such as bindless textures, combining meshes into larger buffers, etc.
Opting Out #
If you would like to opt out an entity from automatic batching, you can add the new NoAutomaticBatching component to it.
This is generally for cases where you are doing custom, non-standard renderer features that don't play nicely with batching's assumptions. For example, it assumes view bindings are constant across draws and that Bevy's-built-in entity batching logic is used.
The Road to GPU-driven Rendering #
Bevy's renderer performance for 2D and 3D meshes can improve a lot. There are bottlenecks on both the CPU and GPU side, which can be lessened to give significantly higher frame rates. As always with Bevy, we want to make the most of the platforms you use, from the constraints of WebGL2 and mobile devices, to the highest-end native discrete graphics cards. A solid foundation can support all of this.
In Bevy 0.12 we have started reworking rendering data structures, data flow, and draw patterns to unlock new optimizations. This enabled the Automatic Batching and Instancing we landed in Bevy 0.12 and also helps pave the way for other significant wins in the future, such as GPU-driven rendering. We aren't quite ready for GPU-driven rendering, but we've started down that path in Bevy 0.12!
What are CPU and GPU-driven rendering? #
CPU-driven rendering is where draw commands are created on the CPU. In Bevy this means "in Rust code", more specifically in render graph nodes. This is how Bevy currently kicks off draws.
In GPU-driven rendering, the draw commands are encoded on the GPU by compute shaders. This leverages GPU parallelism, and unlocks more advanced culling optimizations that are infeasible to do on the CPU, among many other methods that bring large performance benefits.
What needs to change? #
Historically Bevy's general GPU data pattern has been to bind each piece of data per-entity and issue a draw call per-entity. In some cases we did store data in uniform buffers in "array style" and accessed with dynamic offsets, but this still resulted in rebinding at each offset.
All of this rebinding has performance implications, both on the CPU and the GPU. On the CPU, it means encoding draw commands has many more steps to process, taking more time than necessary. On the GPU (and in the graphics API), it means many more rebinds and separate draw commands.
Avoiding rebinding is both a big performance benefit for CPU-driven rendering and is necessary to enable GPU-driven rendering.
To avoid rebinds, the general data pattern we are aiming for is:
- For each data type (meshes, materials, transforms, textures), create a single array (or a small number of arrays) containing all of the items of that data type
- Bind these arrays a small number of times (ideally once), avoiding per-entity/per-draw rebinds
In Bevy 0.12 we've started this process in earnest! We've made a number of architectural changes that are already yielding fruit. Thanks to these changes, we can now automatically batch and instance draws for entities with the exact same mesh and material. And as we progress further down this path, we can batch/instance across a wider variety of cases, cutting out more and more CPU work until eventually we are "fully GPU-driven".
Reorder Render Sets #
The order of draws needs to be known for some methods of instanced draws so that the data can be laid out, and looked up in order. For example, when per-instance data is stored in an instance-rate vertex buffer.
The render set order before Bevy 0.12 caused some problems with this as data had to be prepared (written to the GPU) before knowing the draw order. Not ideal when our plan is to have an ordered list of entity data on the GPU! The previous order of sets was:

This caused friction (and suboptimal instancing) in a number of current (and planned) renderer features. Most notably in previous versions of Bevy, it caused these problems for sprite batching.
The new render set order in 0.12 is:

PrepareAssets was introduced because we only want to queue entities for drawing if their assets have been prepared. Per-frame data preparation still happens in the Prepare set, specifically in its PrepareResources subset. That is now after Queue and Sort, so the order of draws is known. This also made a lot more sense for batching, as it is now known at the point of batching whether an entity that is of another type in the render phase needs to be drawn. Bind groups now have a clear subset where they should be created ... PrepareBindGroups.
BatchedUniformBuffer and GpuArrayBuffer #
OK, so we need to put many pieces of data of the same type into buffers in a way that we can bind them as few times as possible and draw multiple instances from them. How can we do that?
In previous versions of Bevy, per-instance MeshUniform data is stored in a uniform buffer with each instance's data aligned to a dynamic offset. When drawing each mesh entity, we update the dynamic offset, which can be close in cost to rebinding. It looks like this:

Instance-rate vertex buffers are one way, but they are very constrained to having a specific order. They are/may be suitable for per-instance data like mesh entity transforms, but they can't be used for material data. The other main options are uniform buffers, storage buffers, and data textures.
WebGL2 does not support storage buffers, only uniform buffers. Uniform buffers have a minimum guaranteed size per binding of 16kB on WebGL2. Storage buffers, where available, have a minimum guaranteed size of 128MB.
Data textures are far more awkward for structured data. And on platforms that don't support linear data layouts, they will perform worse.
Given these constraints, we want to use storage buffers on platforms where they are supported, and we want to use uniform buffers on platforms where they are not supported (ex: WebGL 2).
BatchedUniformBuffer #
For uniform buffers, we have to assume that on WebGL2 we may only be able to access 16kB of data at a time. Taking an example, MeshUniform requires 144 bytes per instance, which means we can have a batch of 113 instances per 16kB binding. If we want to draw more than 113 entities in total, we need a way of managing a uniform buffer of data that can be bound at a dynamic offset per batch of instances. This is what BatchedUniformBuffer is designed to solve.
BatchedUniformBuffer looks like this:

Notice how the instance data can be packed much more tightly, fitting the same amount of used data in less space. Also, we only need to update the dynamic offset of the binding for each batch.
GpuArrayBuffer #
Given that we need to support both uniform and storage buffers for a given data type, this increases the level of complexity required to implement new low-level renderer features (both in Rust code and in shaders). When confronted with this complexity, some developers might choose instead only use storage buffers (effectively dropping support for WebGL 2).
To make it as easy as possible to support both storage types, we developed GpuArrayBuffer. This is a generic collection of T values that abstracts over BatchedUniformBuffer and StorageBuffer. It will use the right storage for the current platform / GPU.
The data in a StorageBuffer looks like this:

All the instance data can be placed directly one after the other, and we only have to bind once. There is no need for any dynamic offset binding, so there is no need for any padding for alignment.
Check out this annotated code example that illustrates using GpuArrayBuffer to support both uniform and storage buffer bindings.
2D / 3D Mesh Entities using GpuArrayBuffer #
The 2D and 3D mesh entity rendering was migrated to use GpuArrayBuffer for the mesh uniform data.
Just avoiding the rebinding of the mesh uniform data buffer gives about a 6% increase in frame rates!
EntityHashMap Renderer Optimization #
Since Bevy 0.6, Bevy's renderer has extracted data from the "main world" into a separate "render world". This enables Pipelined Rendering, which renders frame N in the render app, while the main app simulates frame N+1.
Part of the design involves clearing the render world of all entities between frames. This enables consistent Entity mapping between the main and render worlds while still being able to spawn new entities in the render world that don't exist in the main world.
Unfortunately, this ECS usage pattern also incurred some significant performance problems. To get good "linear iteration read performance", we wanted to use "table storage" (Bevy's default ECS storage model). However in the renderer, entities are cleared and respawned each frame, components are inserted across many systems and different parts of the render app schedule. This resulted in a lot of "archetype moves" as new components were inserted from various renderer contexts. When an entity moves to a new archetype, all of its "table storage" components are copied into the new archetype's table. This can be expensive across many archetype moves and/or large table moves.
This was unfortunately leaving a lot of performance on the table. Many ideas were discussed over a long period for how to improve this.
The Path Forward #
The main two paths forward were:
- Persist render world entities and their component data across frames
- Stop using entity table storage for storing component data in the render world
We have decided to explore option (2) for Bevy 0.12 as persisting entities involves solving other problems that have no simple and satisfactory answers (ex: how do we keep the worlds perfectly in sync without leaking data). We may find those answers eventually, but for now we chose the path of least resistance!
We landed on using HashMap<Entity, T> with an optimized hash function designed by @SkiFire13, and inspired by rustc-hash. This is exposed as EntityHashMap and is the new way to store component data in the render world.
This yielded significant performance wins.
Usage #
The easiest way to use it is to use the new ExtractInstancesPlugin. This will extract all entities matching a query, or only those that are visible, extracting multiple components at once into one target type.
It is a good idea to group component data that will be accessed together into one target type to avoid having to do multiple lookups.
To extract two components from visible entities:
app.add_plugins;
Sprite Instancing #
In previous versions of Bevy, Sprites were rendered by generating a vertex buffer containing 4 vertices per sprite with position, UV, and possibly color data. This has proven to be very effective. However, having to split batches of sprites into multiple draws because they use a different color is suboptimal.
Sprite rendering now uses an instance-rate vertex buffer to store the per-instance data. Instance-rate vertex buffers are stepped when the instance index changes, rather than when the vertex index changes. The new buffer contains an affine transformation matrix that enables translation, scaling, and rotation in one transform. It contains per-instance color, and UV offset and scale.
This retains all the functionality of the previous method, enables the additional flexibility of any sprite being able to have a color tint and all still be drawn in the same batch, and uses a total of 80 bytes per sprite, versus 144 bytes previously.
This resulted in a performance improvement of up to 40% versus the previous method!
Rusty Shader Imports #
Bevy shaders now use Rust-like shader imports:
// old
#import forward_io VertexOutput
// new
#import VertexOutput
Like Rust imports, you can use curly braces to import multiple items. Multi-level nesting is also now supported!
// old
#import pbr_functions alpha_discard, apply_pbr_lighting
#import bevy_pbr mesh_bindings
// new
#import
Like Rust modules, you can now import partial paths:
#import path
// later in the shader
function;
You can also now use fully qualified paths without importing:
pbr
Rusty Imports remove a number of "API weirdness" gotchas from the old system and expand the capabilities of the import system. And by reusing Rust syntax and semantics, we remove the need for Bevy users to learn a new system.
glTF Emissive Strength #
Bevy now reads and uses the KHR_materials_emissive_strength glTF material extension when loading glTF assets. This adds support for emissive materials when importing glTF from programs like Blender. Each of these cubes has increasing emissive strength:

Import Second UV Map In glTF Files #
Bevy 0.12 now imports the second UV map (TEXCOORD1 or UV1) if it is defined in glTF files and exposes it to shaders. Conventionally this is often used for lightmap UVs. This was an often requested feature and it unlocks lightmapping scenarios (both in custom user shaders and in future Bevy releases).
Wireframe Improvements #
The wireframes now use Bevy's Material abstraction. This means it will automatically use the new batching and instancing features while being easier to maintain. This change also made it easier to add support for colored wireframe. You can configure the color globally or per mesh using the WireframeColor component. It's also now possible to disable wireframe rendering by using the NoWireframe component.

External Renderer Context #
Historically Bevy's RenderPlugin has been fully responsible for initializing the wgpu render context. However some 3rd party Bevy Plugins, such as this work-in-progress bevy_openxr plugin, require more control over renderer initialization.
Therefore in Bevy 0.12, we've made it possible to pass in the wgpu render context at startup. This means the 3rd party bevy_openxr plugin can be a "normal" Bevy plugin without needing to fork Bevy!
Here is a quick video of Bevy VR, courtesy of bevy_openxr!
Bind Group Ergonomics #
When defining "bind groups" for low-level renderer features, we use the following API:
render_device.create_bind_group;
This works reasonably well, but for large numbers of bind groups, the BindGroupEntry boilerplate makes it harder than necessary to read and write everything (and keep the indices up to date).
Bevy 0.12 adds additional options:
// Sets the indices automatically using the index of the tuple item
render_device.create_bind_group;
// Manually sets the indices, but without the BindGroupEntry boilerplate!
render_device.create_bind_group;
One-Shot Systems #
Ordinarily, systems run once per frame, as part of a schedule. But this isn't always the right fit. Maybe you're responding to a very rare event like in a complex turn-based game, or simply don't want to clutter your schedule with a new system for every single button. One-shot systems flip that logic on its head, and provide you the ability to run arbitrary logic on demand, using the powerful and familiar system syntax.
;
There are three simple steps to using one-shot systems: register a system, store its SystemId, and then use either exclusive world access or commands to run the corresponding system.
A lot becomes possible with just that, however SystemIds really start showing their power, when they're wrapped into components.
use SystemId;
;
// calling all callbacks!
One-shot systems can then be attached to UI elements, like buttons, actions in an RPG, or any other entity. You might even feel inspired to implement the Bevy scheduling graph with one-shot systems and aery (let us know how that goes, by the way).
One-shot systems are very flexible. They can be nested, so you can call run_system from within a one-shot system. It's possible to have multiple instances of one system registered at a time, each with their own Local variables and cached system state. It also plays nice with asset-driven workflows: recording a mapping from a string to an identifier in a serialized callback is much nicer than trying to do so with Rust functions!
Still, one-shot systems are not without their limitations. Currently, exclusive systems and systems designed for system piping (with either an In parameter or a return type) can't be used at all. You also can't call a one-shot systems from itself, recursion isn't possible. Lastly, one-shot systems are always evaluated sequentially, rather than in parallel. While this reduces both complexity and overhead, for certain workloads this can be meaningfully slower than using a schedule with a parallel executor.
However, when you're just prototyping or writing a unit test, it can be a real hassle: two whole functions and some weird identifier? For these situations, you can use the World::run_system_once method.
use RunSystemOnce;
;
let mut world = new;
world.;
world.run_system_once; // prints 1
world.run_system_once; // prints 2
This is great for unit testing systems and queries, and it's both lower overhead and simpler to use. However, there is one caveat. Some systems have state, either in the form of Local arguments, change detection, or EventReaders. This state isn't saved between two run_system_once calls, creating odd behavior. The Locals reset every run, while change detection will always detect data as added/changed. Be careful and you'll be alright.
system.map #
Bevy 0.12 adds a new system.map() function, which is a cheaper and more ergonomic alternative to system.pipe().
Unlike system.pipe(), system.map() just takes a normal closure (instead of another system) that accepts the output of the system as its parameter:
app.add_systems;
// An adapter that logs errors
Bevy provides built in error, warn, debug, and info adapters that can be used with system.map() to log errors at each of these levels.
Simplify Parallel Iteration Method #
Bevy 0.12 makes the parallel Query iterator for_each() compatible with both mutable and immutable queries, reducing API surface and removing the need to write mut twice:
// Before:
query.par_iter_mut.for_each_mut;
// After:
query.par_iter_mut.for_each;
Disjoint Mutable World Access Via EntityMut #
Bevy 0.12 supports safely accessing multiple EntityMut values at once, meaning you can mutate multiple entities (with access to all of their components) at the same time.
let = world.many_entities_mut;
*entity1..unwrap = *entity2..unwrap;
This also works in queries:
// This would not have been expressible in previous Bevy versions
// Now it is totally valid!
You can now mutably iterate all entities and access arbitrary components within them:
for mut entity in world.iter_entities_mut
This required reducing the access scope of EntityMut to only the entity it accesses (previously it had escape hatches that allowed direct World access). Use EntityWorldMut for an equivalent to the old "global access" approach.
Unified configure_sets API #
Bevy's Schedule-First API introduced in Bevy 0.11 unified most of the ECS scheduler API surface under a single add_systems API. However, we didn't do a unified API for configure_sets, meaning there were two different APIs:
app.configure_set;
app.configure_setsIn Bevy 0.12, we have unified these under a single API to align with the patterns we've used elsewhere and cut down on unnecessary API surface:
app.configure_sets;
app.configure_setsUI Materials #
Bevy's material system has been brought to Bevy UI thanks to the new UiMaterial:

This "circle" UI Node is drawn with a custom shader:
#import UiVertexOutput
@group @binding
input: CircleMaterial;
@fragment
@location
And just like other Bevy material types, it is simple to set up in code!
// Register the material plugin in your App
app.add_plugins
// Later in your app, spawn the UI node with your material!
commands.spawn;
UI Node Outlines #
Bevy's UI nodes now support outlines "outside the borders" of UI nodes via the new Outline component. Outline does not occupy any space in the layout. This is different than Style::border, which exists "as part of" the node in the layout:

commands.spawn
Unified Time #
Bevy 0.12 brings two major quality of life improvements to FixedUpdate.
Timenow returns the contextually correct values for systems running inFixedUpdate. (As such,FixedTimehas been removed.)FixedUpdatecan no longer snowball into a "death spiral" (where the app freezes becauseFixedUpdatesteps are enqueued faster than it can run them).
The FixedUpdate schedule and its companion FixedTime resource were introduced in Bevy 0.10, and it soon became apparent that FixedTime was lacking. Its methods were different from Time and it didn't even track "total time elapsed" like Time did, to name a few examples. Having two different "time" APIs also meant you had to write systems to specifically support "fixed timestep" or "variable timestep" and not both. It was desirable to not have this split as it can lead to incompatibilities between plugins down the road (which is sometimes the case with plugins in other game engines).
Now, you can just write systems that read Time and schedule them in either context.
// This system will see a constant delta time if scheduled in `FixedUpdate` or
// a variable delta time if scheduled in `Update`.
Most systems should continue to use Time, but behind the scenes, the methods from previous APIs have been refactored into four clocks:
Time<Real>Time<Virtual>Time<Fixed>Time<()>
Time<Real> measures the true, unedited frame and app durations. For diagnostics/profiling, use that one. It's also used to derive the others. Time<Virtual> can be sped up, slowed down, and paused, and Time<Fixed> chases Time<Virtual> in fixed increments. Lastly, Time<()> is automatically overwritten with the current value of Time<Fixed> or Time<Virtual> upon entering or exiting FixedUpdate. When a system borrows Time, it actually borrows Time<()>.
Try the new time example to get a better feel for these resources.
The fix for the windup problem was limiting how much Time<Virtual> can advance from a single frame. This then limits how many times FixedUpdate can be queued for the next frame, and so things like frame lag or your computer waking up from a long sleep can no longer cause a death spiral. So now, the app won't freeze, but things happening in FixedUpdate will appear to slow down since it'll be running at a temporarily reduced rate.
ImageLoader Settings #
To take advantage of the new AssetLoader settings in Bevy Asset V2, we've added ImageLoaderSettings to ImageLoader.
This means that you can now configure the sampler, SRGB-ness, and the format, on a per-image basis. These are the defaults, as they appear in Bevy Asset V2 meta files:
When set to Default, the image will use whatever is configured in ImagePlugin::default_sampler.
However, you can set these values to whatever you want!
GamepadButtonInput #
Bevy generally provides two ways to handle input of a given type:
- Events: receive a stream of input events in the order they occur
- The
InputResource: read the current state of the input
One notable exception was GamepadButton, which was only available via the Input resource. Bevy 0.12 adds a new GamepadButtonInput event, filling this gap.
SceneInstanceReady Event #
Bevy 0.12 adds a new SceneInstanceReady event, which makes it easy to listen for a specific scene instance to be ready. "Ready" in this case means "fully spawned as an entity".
;
Split Computed Visibility #
The ComputedVisibility component has now been split into InheritedVisibility (visible in the hierarchy) and ViewVisibility (visible from a view), making it possible to use Bevy's built-in change detection on both sets of data separately.
ReflectBundle #
Bevy now supports "Bundle reflection" via ReflectBundle:
This makes it possible to create and interact with ECS bundles using Bevy Reflect, meaning you can do these operations dynamically at runtime. This is useful for scripting and asset scenarios.
Reflect Commands #
It is now possible to insert and remove reflect components from an entity in a normal system via new functions on Commands!
;
The above commands use the AppTypeRegistry by default. If you use a different TypeRegistry then you can use the ...with_registry commands instead.
See ReflectCommandExt for more examples and documentation
Limit Background FPS #
If an app has no window in focus, Bevy will now limit its update rate (to 60Hz by default).
Before, many Bevy apps running on desktop operating systems (particularly macOS) would see spikes in CPU usage whenever their windows were minimized or completely covered, even with VSync enabled. The reason for this is that many desktop window managers ignore VSync for windows that aren't visible. As VSync normally limits how often an app updates, that speed limit vanishes while it's effectively disabled.
Now, apps running in the background will sleep in between updates to limit their FPS.
The one caveat is that most operating systems will not report if a window is visible, only if it has focus. So the throttle is based on focus, not visibility. 60Hz was then chosen as the default to maintain high FPS in cases where the window is not focused but still visible.
AnimationPlayer API Improvements #
The AnimationPlayer now has new methods for controlling playback, and utilities for checking if an animation is playing or completed, and getting its AnimationClip handle.
set_elapsed has been removed in favor of seek_to. elapsed now returns the actual elapsed time and is not affected by the animation speed. stop_repeating has been removed in favor of set_repeat(RepeatAnimation::Never).
let mut player = q_animation_player.single_mut;
// Check if an animation is complete.
if player.is_finished
// Get a handle to the playing AnimationClip.
let clip_handle = player.animation_clip;
// Seek to 1s in the current clip.
player.seek_to;
Ignore Ambiguous Components and Resources #
Ambiguity Reporting is an optional feature of Bevy's scheduler. When enabled it reports conflicts between systems that modify the same data, but are not ordered in relation to each other. While some reported conflicts can cause subtle bugs, many do not. Bevy has a couple existing methods and two new ones for ignoring these.
The existing APIs: ambiguous_with, which ignores conflicts between specific sets, and ambiguous_with_all, which ignores all conflicts with the set it's applied to. In addition, there are now 2 new APIs that let you ignore conflicts on a type of data, allow_ambiguous_component and allow_ambiguous_resource. These ignore all conflicts between systems on that specific type, component or resource, in a world.
;
// These systems are ambiguous on R
let mut app = new;
app.configure_schedules;
app.insert_resource;
app.add_systems;
app.;
// Running the app does not error.
app.update;
Bevy is now using this to ignore conflicts between the Assets<T> resources. Most of these ambiguities are modifying different assets and thus do not matter.
Spatial Audio API Ergonomics #
A simple "stereo" (non-HRTF) spatial audio implementation was heroically put together at the last minute for Bevy 0.10, but the implementation was somewhat bare-bones and not very user-friendly. Users needed to write their own systems to update audio sinks with emitter and listener positions.
Now users can just add a TransformBundle to their AudioBundles and Bevy will take care of the rest!
commands.spawn;
Pitch Audio Source #
Audio can now be played by pitch, which is useful to debug audio issues, to use as a placeholder, or for programmatic audio.
A Pitch audio source can be created from its frequency and its duration, and then be used as a source in a PitchBundle.
Audio is generated at the given frequency using a sine wave. More complex sounds can be created by playing several pitch audio sources at the same time, like chords or hamonics.
Added HSL methods to Color struct #
You can now use h(), s(), l() together with their set_h(), set_s(), set_l() and with_h(), with_s(), with_l() variants to manipulate Hue, Saturation and Lightness values of a Color struct without cloning. Previously you could do that with only RGBA values.
// Returns HSL component values
let color = ORANGE;
let hue = color.h;
// ...
// Changes the HSL component values
let mut color = PINK;
color.set_s;
// ...
// Modifies existing colors and returns them
let color = VIOLET.with_l;
// ...
Reduced Tracing Overhead #
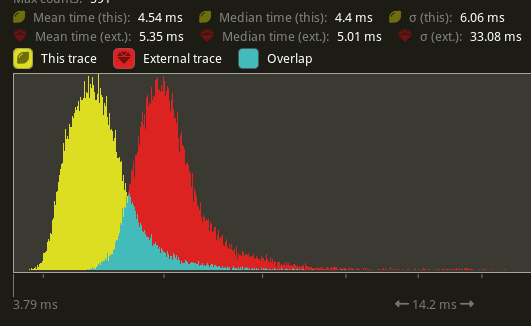
Bevy uses the tracing library to measure system running time (among other things). This is useful for determining where bottlenecks in frame time are and measuring performance improvements. These traces can be visualized using the tracy tool. However, using tracing's spans has a significant overhead to it. A large part of the per-span overhead is due to allocating the string description of the span. By caching the spans for systems, commands, and parallel iteration, we have significantly reduced the CPU time overhead when using tracing. In the PR that introduced system span caching, our "many foxes" stress test went from 5.35 ms to 4.54 ms. In the PR that added caching for the parallel iteration spans, our "many cubes" stress test went from 8.89 ms to 6.8 ms.
AccessKit Integration Improvements #
Bevy 0.10's AccessKit integration made it incredibly easy for the engine to take the lead and push updates to the accessibility tree. But as any good dance partner knows, sometimes it's best not to lead but to follow.
This release adds the ManageAccessibilityUpdates resource which, when set to false, stops the engine from updating the tree on its own. This paves the way for third-party UIs with Bevy and AccessKit integration to send updates directly to Bevy. When the UI is ready to return control, ManageAccessibilityUpdates is set to true Bevy picks up where it left off and starts sending updates again.
AccessKit itself was also simplified, and this release capitalizes on that to shrink the surface area of our integration. If you're curious about how things work internally or want to help, the bevy_a11y crate is now more approachable than ever.
TypePath Migration #
As a followup to the introduction of Stable TypePath in Bevy 0.11, Bevy Reflect now uses TypePath instead of type_name. A reflected type's TypePath is now accessible via TypeInfo and DynamicTypePath and type_name methods have been removed.
Improved bevymark Example #
The bevymark example needed to be improved to enable benchmarking the batching / instanced draw changes. Modes were added to:
- draw 2D quad meshes instead of sprites:
--mode mesh2d - vary the per-instance color data instead of only varying the colour per wave of birds:
--vary-per-instance - generate a number of material / sprite textures and randomly choose from them either per wave or per instance depending on the vary per instance setting:
--material-texture-count 10 - spawn the birds in random z order (new default), or in draw order:
--ordered-z
This allows benchmarking of different situations for batching / instancing in the next section.
CI Improvements #
To help ensure examples are reusable outside of the Bevy repository, CI will now fail if an example uses an import from bevy_internal instead of bevy.
Additionally, the daily mobile check job now builds on more iOS and Android devices:
- iPhone 13 on iOS 15
- iPhone 14 on iOS 16
- iPhone 15 on iOS 17
- Xiaomi Redmi Note 11 on Android 11
- Google Pixel 6 on Android 12
- Samsung Galaxy S23 on Android 13
- Google Pixel 8 on Android 14
Example tooling improvements #
The example showcase tool can now build all examples for WebGL2 or WebGPU. This is used to update the website with all Wasm-compatible examples, which you can find here for WebGL2, or here for WebGPU.
It is now also capable of capturing a screenshot while running all examples:
Some options are available to help with the execution, you can check them with --help.
Those screenshots are displayed on the example pages on the website, and can be used to check that a PR didn't introduce a visible regression.
Example execution in CI #
All examples are now executed in CI on Windows with DX12, and on Linux with Vulkan. When possible, a screenshot is taken and compared to the last execution. If an example crashes, the log is saved. The mobile example is also executed on the same devices as the daily mobile check job.
A report of all those executions is built and available here.
If you want to help sponsor tests on more platforms, get in touch!
What's Next? #
We have plenty of work in progress! Some of this will likely land in Bevy 0.13.
Check out the Bevy 0.13 Milestone for an up-to-date list of current work being considered for Bevy 0.13.
- Bevy Scene and UI Evolution: We are hard at work building out a new Scene and UI system for Bevy. We're experimenting with a brand new holistic Scene / UI system that will hopefully serve as the foundation for the Bevy Editor and make defining scenes in Bevy much more flexible, capable, and ergonomic.
- More Batching/Instancing Improvements: Put skinned mesh data into storage buffers to enable instanced drawing of skinned mesh entities with the same mesh/skin/material. Put material data in the new GpuArrayBuffer to enable batching of draws of entities with the same mesh, material type, and textures, but different material data.
- GPU-Driven Rendering: We plan on driving rendering via the GPU by creating draw calls in compute shaders (on platforms that support it). We have experiments using meshlets and plan to explore other approaches as well. This will involve putting textures into bindless texture arrays and putting meshes in one big buffer to avoid rebinds.
- Exposure Settings: Control camera exposure settings to change the feel and mood of your renders!
- GPU Picking: Efficiently select objects with pixel perfect accuracy on the GPU!
- Per-Object Motion Blur: Blur objects as they move using their motion vectors
- UI Node Border Radius and Shadows: Support for border radius and shadows in Bevy UI
- System Stepping: Debug your app by running systems step by step for a given frame
- Automatic Sync Points: Support for automatically inserting sync points between systems with dependencies, removing the need for manual insertion and resolving a common source of errors.
- Lightmap Support: Support for rendering pre-baked lightmaps
Support Bevy #
Sponsorships help make our work on Bevy sustainable. If you believe in Bevy's mission, consider sponsoring us ... every bit helps!
Contributors #
Bevy is made by a large group of people. A huge thanks to the 185 contributors that made this release (and associated docs) possible! In random order:
- @miketwenty1
- @viridia
- @d-bucur
- @mamekoro
- @jpsikstus
- @johanhelsing
- @ChristopherBiscardi
- @GitGhillie
- @superdump
- @RCoder01
- @photex
- @geieredgar
- @cbournhonesque-sc
- @A-Walrus
- @Nilirad
- @nicoburns
- @hate
- @CrumbsTrace
- @SykikXO
- @DevinLeamy
- @jancespivo
- @ethereumdegen
- @Trashtalk217
- @pcwalton
- @maniwani
- @robtfm
- @stepancheg
- @kshitijaucharmal
- @killercup
- @ricky26
- @mockersf
- @mattdm
- @softmoth
- @tbillington
- @skindstrom
- @CGMossa
- @ickk
- @Aceeri
- @Vrixyz
- @Feilkin
- @flisky
- @IceSentry
- @maxheyer
- @MalekiRe
- @torsteingrindvik
- @djeedai
- @rparrett
- @SIGSTACKFAULT
- @Zeenobit
- @ycysdf
- @nickrart
- @louis-le-cam
- @mnmaita
- @basilefff
- @mdickopp
- @gardengim
- @ManevilleF
- @Wcubed
- @PortalRising
- @JoJoJet
- @rj00a
- @jnhyatt
- @ryand67
- @alexmadeathing
- @floppyhammer
- @Pixelstormer
- @ItsDoot
- @SludgePhD
- @cBournhonesque
- @fgrust
- @sebosp
- @ndarilek
- @coreh
- @Selene-Amanita
- @aleksa2808
- @IDEDARY
- @kamirr
- @EmiOnGit
- @wpederzoli
- @Shatur
- @ClayenKitten
- @regnarock
- @hesiod
- @raffaeleragni
- @floreal
- @robojeb
- @konsolas
- @nxsaken
- @ameknite
- @66OJ66
- @Unarmed
- @MarkusTheOrt
- @alice-i-cecile
- @arsmilitaris
- @horazont
- @Elabajaba
- @BrandonDyer64
- @jimmcnulty41
- @SecretPocketCat
- @hymm
- @tadeohepperle
- @Dot32IsCool
- @waywardmonkeys
- @bushrat011899
- @devil-ira
- @rdrpenguin04
- @s-puig
- @denshika
- @FlippinBerger
- @TimJentzsch
- @sadikkuzu
- @paul-hansen
- @Neo-Zhixing
- @SkiFire13
- @wackbyte
- @JMS55
- @rlidwka
- @urben1680
- @BeastLe9enD
- @rafalh
- @ickshonpe
- @bravely-beep
- @Kanabenki
- @tormeh
- @opstic
- @iiYese
- @525c1e21-bd67-4735-ac99-b4b0e5262290
- @nakedible
- @Cactus-man
- @MJohnson459
- @rodolphito
- @MrGVSV
- @cyqsimon
- @DGriffin91
- @danchia
- @NoahShomette
- @hmeine
- @Testare
- @nicopap
- @soqb
- @cevans-uk
- @papow65
- @ptxmac
- @suravshresth
- @james-j-obrien
- @MinerSebas
- @ottah
- @doonv
- @pascualex
- @CleanCut
- @yrns
- @Quicksticks-oss
- @HaNaK0
- @james7132
- @awtterpip
- @aevyrie
- @ShadowMitia
- @tguichaoua
- @okwilkins
- @Braymatter
- @Cptn-Sherman
- @jakobhellermann
- @SpecificProtagonist
- @jfaz1
- @tsujp
- @Serverator
- @lewiszlw
- @dmyyy
- @cart
- @teoxoy
- @StaffEngineer
- @MrGunflame
- @pablo-lua
- @100-TomatoJuice
- @OneFourth
- @anarelion
- @VitalyAnkh
- @st0rmbtw
- @fornwall
- @ZacHarroldC5
- @NiseVoid
- @Dworv
- @NiklasEi
- @arendjr
- @Malax
Full Changelog #
A-ECS + A-Diagnostics #
A-ECS + A-Scenes #
A-Scenes #
- Move scene spawner systems to SpawnScene schedule
- Add
SceneInstanceReady - Add
SpawnSceneto prelude - Finish documenting
bevy_scene - Only attempt to copy resources that still exist from scenes
- Correct Scene loader error description
A-Tasks + A-Diagnostics #
A-Tasks #
- elaborate on TaskPool and bevy tasks
- Remove Resource and add Debug to TaskPoolOptions
- Fix clippy lint in single_threaded_task_pool
- Remove dependecies from bevy_tasks' README
- Allow using async_io::block_on in bevy_tasks
- add test for nested scopes
- Global TaskPool API improvements
A-Audio + A-Windowing #
A-Animation + A-Transform #
A-Transform #
- Update
GlobalTransformon insertion - Add
Without<Parent>filter tosync_simple_transforms' orphaned entities query - Fix ambiguities in transform example
A-App #
- Add
track_callertoApp::add_plugins - Remove redundant check for
AppExitevents inScheduleRunnerPlugin - fix typos in crates/bevy_app/src/app.rs
- fix typos in crates/bevy_app/src/app.rs
- fix run-once runners
A-ECS + A-App #
- Add configure_schedules to App and Schedules to apply
ScheduleBuildSettingsto all schedules - Only run event systems if they have tangible work to do
A-Rendering + A-Gizmos #
A-Rendering + A-Diagnostics #
- Include note of common profiling issue
- Enhance many_cubes stress test use cases
- GLTF loader: handle warning NODE_SKINNED_MESH_WITHOUT_SKIN
A-Rendering + A-Reflection #
A-Windowing #
- Add option to toggle window control buttons
- Fixed: Default window is now "App" instead of "Bevy App"
- improve documentation relating to
WindowPluginandWindow - Improve
bevy_winitdocumentation - Change
WinitPlugindefaults to limit game update rate when window is not visible - User controlled window visibility
- Check cursor position for out of bounds of the window
- Fix doc link in transparent_window example
- Wait before making window visible
- don't create windows on winit StartCause::Init event
- Fix the doc warning attribute and document remaining items for
bevy_window - Revert "macOS Sonoma (14.0) / Xcode 15.0 — Compatibility Fixes + Docs…
- Revert "macOS Sonoma (14.0) / Xcode 15.0 — Compatibility Fixes + Docs…
- Allow Bevy to start from non-main threads on supported platforms
- Prevent black frames during startup
- Slightly improve
CursorIcondoc. - Fix typo in window.rs
A-Gizmos #
- Replace AHash with a good sequence for entity AABB colors
- gizmo plugin lag bugfix
- Clarify immediate mode in
Gizmosdocumentation - Fix crash when drawing line gizmo with less than 2 vertices
- Document that gizmo
depth_biashas no effect in 2D
A-Utils #
- change 'collapse_type_name' to retain enum types
- bevy_derive: Fix
#[deref]breaking other attributes - Move default docs
A-Rendering + A-Assets #
- Import the second UV map if present in glTF files.
- fix custom shader imports
- Add
ImageSamplerDescriptoras an image loader setting
A-ECS #
- Add the Has world query to bevy_ecs::prelude
- Simplify parallel iteration methods
- Fix safety invariants for
WorldQuery::fetchand simplify cloning - Derive debug for ManualEventIterator
- Add
EntityMap::clear - Add a paragraph to the lifetimeless module doc
- opt-out
multi-threadedfeature flag - Fix
ambiguous_withbreaking run conditions - Add
RunSystem - Add
replace_if_neqtoDetectChangesMut - Adding
Copy, Clone, Debugto derived traits ofExecutorKind - Fix incorrect documentation link in
DetectChangesMut - Implement
DebugforUnsafeWorldCell - Relax In/Out bounds on impl Debug for dyn System
- Improve various
Debugimplementations - Make
run_if_innerpublic and rename torun_if_dyn - Refactor build_schedule and related errors
- Add
system.map(...)for transforming the output of a system - Reorganize
EventsandEventSequencecode - Replaced EntityMap with HashMap
- clean up configure_set(s) erroring
- Relax more
Syncbounds onLocal - Rename
ManualEventIterator - Replaced
EntityCommandImplementation forFnOnce - Add a variant of
Events::updatethat returns the removed events - Move schedule name into
Schedule - port old ambiguity tests over
- Refactor
EventReader::itertoread - fix ambiguity reporting
- Fix anonymous set name stack overflow
- Fix unsoundness in
QueryState::is_empty - Add panicking helpers for getting components from
Query - Replace
IntoSystemSetConfigwithIntoSystemSetConfigs - Moved
get_component(_unchecked_mut)fromQuerytoQueryState - Fix naming on "tick" Column and ComponentSparseSet methods
- Clarify a comment in Option WorldQuery impl
- Return a boolean from
set_if_neq - Rename RemovedComponents::iter/iter_with_id to read/read_with_id
- Remove some old references to CoreSet
- Use single threaded executor for archetype benches
- docs: Improve some
ComponentIddoc cross-linking. - One Shot Systems
- Add mutual exclusion safety info on filter_fetch
- add try_insert to entity commands
- Improve codegen for world validation
- docs: Use intradoc links for method references.
- Remove States::variants and remove enum-only restriction its derive
as_deref_mut()method for Mut-like types- refactor: Change
Option<With<T>>query params toHas<T> - Hide
UnsafeWorldCell::unsafe_world - Add a public API to ArchetypeGeneration/Id
- Ignore ambiguous components or resources
- Use chain in breakout example
ParamSets containing non-send parameters should also be non-send- Replace all labels with interned labels
- Fix outdated comment referencing CoreSet
A-Rendering + A-Math #
A-UI #
- Fix for vertical text bounds and alignment
- UI extraction order fix
- Update text example using default font
- bevy_ui: fix doc formatting for some Style fields
- Remove the
With<Parent>query filter frombevy_ui::render::extract_uinode_borders - Fix incorrent doc comment for the set method of
ContentSize - Improved text widget doc comments
- Change the default for the
measure_funcfield ofContentSizeto None. - Unnecessary line in game_menu example
- Change
UiScaleto a tuple struct - Remove unnecessary doc string
- Add some missing pub in ui_node
- UI examples clean up
round_ties_upfix- fix incorrect docs for
JustifyItemsandJustifySelf - Added
Val::ZEROConstant - Cleanup some bevy_text pipeline.rs
- Make
GridPlacement's fields non-zero and add accessor functions. - Remove
Val'stry_*arithmetic methods - UI node bundle comment fix
- Do not panic on non-UI child of UI entity
- Rename
Valevaluatetoresolveand implement viewport variant support - Change
Urect::width&Urect::heightto be const TextLayoutInfo::sizeshould hold the drawn size of the text, and not a scaled value.impl From<String>andFrom<&str>forTextSection- Remove z-axis scaling in
extract_text2d_sprite - Fix doc comments for align items
- Add tests to
bevy_ui::Layout - examples: Remove unused doc comments.
- Add missing
bevy_textfeature attribute toTextBundlefrom impl - Move
Valintogeometry - Derive Serialize and Deserialize for UiRect
ContentSizereplacement fix- Round UI coordinates after scaling
- Have a separate implicit viewport node per root node + make viewport node
Display::Grid - Rename
num_font_atlasestolen. - Fix documentation for ui node Style
text_wrap_debugscale factor commandline args- Store both the rounded and unrounded node size in Node
- Various accessibility API updates.
- UI node outlines
- Implement serialize and deserialize for some UI types
- Tidy up UI node docs
- Remove unused import warning when default_font feature is disabled
- Fix crash with certain right-aligned text
- Add some more docs for bevy_text.
- Implement
NegforVal normalizemethod forRect- don't Implement
DisplayforVal - [bevy_text] Document what happens when font is not specified
- Update UI alignment docs
- Add stack index to
Node - don't Implement
DisplayforVal
A-Animation #
- Fix doc typo
- Expose
animation_clippaths - animations: convert skinning weights from unorm8x4 to float32x4
- API updates to the AnimationPlayer
- only take up to the max number of joints
- check root node for animations
- Fix morph interpolation
A-Pointers #
A-Assets + A-Reflection #
A-Rendering + A-Hierarchy #
A-ECS + A-Tasks #
A-Reflection + A-Utils #
A-Reflection + A-Math #
A-Hierarchy #
A-Input #
- input: allow multiple gamepad inputs to be registered for one button in one frame
- Bevy Input Docs : lib.rs
- Bevy Input Docs : gamepad.rs
- Add
GamepadButtonInputevent - Bevy Input Docs : the modules
- Finish documenting
bevy_gilrs - Change
AxisSettingslivezone default - docs: Update input_toggle_active example
A-Input + A-Windowing #
- Fix
Window::set_cursor_position - Change
Window::physical_cursor_positionto use the physical size of the window - Fix check that cursor position is within window bounds
A-ECS + A-Reflection #
- implement insert and remove reflected entity commands
- Allow disjoint mutable world access via
EntityMut - Implement
ReflectforState<S>andNextState<S> #[derive(Clone)]onComponent{Info,Descriptor}
A-Math #
- Rename bevy_math::rects conversion methods
- Add glam swizzles traits to prelude
- Rename
BeziertoCubicBezierfor clarity - Add a method to compute a bounding box enclosing a set of points
- re-export
debug_glam_assertfeature - Add
Cubicprefix to all cubic curve generators
A-Build-System #
- only check for bans if the dependency tree changed
- Slightly better message when contributor modifies examples template
- switch CI jobs between windows and linux for example execution
- Check for bevy_internal imports in CI
- Fix running examples on linux in CI
- Bump actions/checkout from 2 to 4
- doc: Remove reference to
clippy::manual-strip. - Only run some workflows on the bevy repo (not forks)
- run mobile tests on more devices / OS versions
- Allow
clippy::type_complexityin more places. - hacks for running (and screenshotting) the examples in CI on a github runner
- make CI less failing on cargo deny bans
- add test on Android 14 / Pixel 8
- Use
clippy::doc_markdownmore.
A-Diagnostics #
A-Rendering + A-Animation #
A-Core #
A-Reflection #
- Fix typo in NamedTypePathDef
- Refactor
pathmodule ofbevy_reflect - Refactor parsing in bevy_reflect path module
- bevy_reflect: Fix combined field attributes
- bevy_reflect: Opt-out attribute for
TypePath - Add reflect path parsing benchmark
- Make it so
ParsedPathcan be passed to GetPath - Make the reflect path parser utf-8-unaware
- bevy_scene: Add
ReflectBundle - Fix comment in scene example
FromResources - Remove TypeRegistry re-export rename
- Provide getters for fields of ReflectFromPtr
- Add TypePath to the prelude
- Improve TypeUuid's derive macro error messages
- Migrate
Quatreflection strategy from "value" to "struct" - bevy_reflect: Fix dynamic type serialization
- bevy_reflect: Fix ignored/skipped field order
A-Rendering + A-Assets + A-Reflection #
A-ECS + A-Time #
A-ECS + A-Hierarchy #
A-Audio #
- Added Pitch as an alternative sound source
- update documentation on AudioSink
- audio sinks don't need their custom drop anymore
- Clarify what happens when setting the audio volume
- More ergonomic spatial audio
A-Rendering + A-UI #
- Remove out-of-date paragraph in
Style::border - Revert "Fix UI corruption for AMD gpus with Vulkan (#9169)"
- Revert "Fix UI corruption for AMD gpus with Vulkan (#9169)"
many_buttonsenhancements- Fix UI borders
- UI batching Fix
- Add UI Materials
A-ECS + A-Reflection + A-Pointers #
No area label #
- Fix typos throughout the project
- Bump Version after Release
- fix
clippy::default_constructed_unit_structsand trybuild errors - delete code deprecated in 0.11
- Drain
ExtractedUiNodesinprepare_uinodes - example showcase - pagination and can build for WebGL2
- example showcase: switch default api to webgpu
- Add some more helpful errors to BevyManifest when it doesn't find Cargo.toml
- Fix path reference to contributors example
- replace parens with square brackets when referencing _mut on
Querydocs #9200 - use AutoNoVsync in stress tests
- bevy_render: Remove direct dep on wgpu-hal.
- Fixed typo in line 322
- custom_material.vert: gl_InstanceIndex includes gl_BaseInstance
- fix typo in a link - Mesh docs
- Improve font size related docs
- Fix gamepad viewer being marked as a non-wasm example
- Rustdoc: Scrape examples
- enable multithreading on benches
- webgl feature renamed to webgl2
- Example Comment Typo Fix
- Fix shader_instancing example
- Update tracy-client requirement from 0.15 to 0.16
- fix bevy imports. windows_settings.rs example
- Fix CI for Rust 1.72
- Swap TransparentUi to use a stable sort
- Replace uses of
entity.insertwith tuple bundles ingame_menuexample - Remove
IntoIteratorimpl for&mut EventReader - remove VecSwizzles imports
- Fix erronenous glam version
- Fixing some doc comments
- Explicitly make instance_index vertex output @interpolate(flat)
- Fix some nightly warnings
- Use default resolution for viewport_debug example
- Refer to "macOS", not "macOS X".
- Remove useless single tuples and trailing commas
- Fix some warnings shown in nightly
- Fix animate_scale scaling z value in text2d example
- "serialize" feature no longer enables the optional "bevy_scene" feature if it's not enabled from elsewhere
- fix deprecation warning in bench
- don't enable filesystem_watcher when building for WebGPU
- Improve doc formatting.
- Fix the
clippy::explicit_iter_looplint - Wslg docs
- skybox.wgsl: Fix precision issues
- Fix typos.
- Add link to
Text2dBundleinTextBundledocs. - Fix some typos
- Fix typos
- Replaced
parking_lotwithstd::sync - Add inline(never) to bench systems
- Android: handle suspend / resume
- Fix some warnings shown in nightly
- Updates for rust 1.73
- Improve selection of iOS device in mobile example
- Update toml_edit requirement from 0.19 to 0.20
- foxes shouldn't march in sync
- Fix tonemapping test patten
- Removed
once_cell - Improve WebGPU unstable flags docs
- shadow_biases: Support different PCF methods
- shadow_biases: Support moving the light position and resetting biases
- Update async-io requirement from 1.13.0 to 2.0.0
- few fmt tweaks
- Derive Error for more error types
- Allow AccessKit to react to WindowEvents before they reach the engine
A-Rendering + A-Build-System #
A-Meta #
- Remove the bevy_dylib feature
- add and fix shields in Readmes
- Added section for contributing and links for issues and PRs
- Fix orphaned contributing paragraph
A-Assets + A-Animation #
A-Editor + A-Diagnostics #
A-Time #
- Fix timers.rs documentation
- Add missing documentation to
bevy_time - Clarify behaviour of
Timer::finished()for repeating timers - ignore time channel error
- Unify
FixedTimeandTimewhile fixing several problems - Time: demote delta time clamping warning to debug
- fix typo in time.rs example
- Example time api
A-Rendering + A-ECS #
A-UI + A-Reflection #
A-Build-System + A-Assets #
A-Rendering #
- Clarify that wgpu is based on the webGPU API
- Return URect instead of (UVec2, UVec2) in Camera::physical_viewport_rect
- fix module name for AssetPath shaders
- Add GpuArrayBuffer and BatchedUniformBuffer
- Update
bevy_window::PresentModeto mirrorwgpu::PresentMode - Stop using unwrap in the pipelined rendering thread
- Fix panic whilst loading UASTC encoded ktx2 textures
- Document
ClearColorConfig - Use GpuArrayBuffer for MeshUniform
- Update docs for scaling_mode field of Orthographic projection
- Fix shader_material_glsl example after #9254
- Improve
Meshdocumentation - Include tone_mapping fn in tonemapping_test_patterns
- Extend the default render range of 2D camera
- Document when Camera::viewport_to_world and related methods return None
- include toplevel shader-associated defs
- Fix post_processing example on webgl2
- use ViewNodeRunner in the post_processing example
- Work around naga/wgpu WGSL instance_index -> GLSL gl_InstanceID bug on WebGL2
- Fix non-visible motion vector text in shader prepass example
- Use bevy crates imports instead of bevy internal. post_processing example
- Make Anchor Copy
- Move window.rs to window/mod.rs in bevy_render
- Reduce the size of MeshUniform to improve performance
- Fix temporal jitter bug
- Fix gizmo lines deforming or disappearing when partially behind the camera
- Make WgpuSettings::default() check WGPU_POWER_PREF
- fix wireframe after MeshUniform size reduction
- fix shader_material_glsl example
- [RAINBOW EFFECT] Added methods to get HSL components from Color
- ktx2: Fix Rgb8 -> Rgba8Unorm conversion
- Reorder render sets, refactor bevy_sprite to take advantage
- Improve documentation relating to
FrustumandHalfSpace - Revert "Update defaults for OrthographicProjection (#9537)"
- Remove unused regex dep from bevy_render
- Split
ComputedVisibilityinto two components to allow for accurate change detection and speed up visibility propagation - Use instancing for sprites
- Enhance bevymark
- Remove redundant math in tonemapping.
- Improve
SpatialBundledocs - Cache depth texture based on usage
- warn and min for different vertex count
- default 16bit rgb/rgba textures to unorm instead of uint
- Fix TextureAtlasBuilder padding
- Add example for
Camera::viewport_to_world - Fix wireframe for skinned/morphed meshes
- generate indices for Mikktspace
- invert face culling for negatively scaled gltf nodes
- renderer init: create a detached task only on wasm, block otherwise
- Cleanup
visibilitymodule - Use a single line for of large binding lists
- Fix a typo in
DirectionalLightBundle - Revert "Update defaults for OrthographicProjection (#9537)"
- Refactor rendering systems to use
let-else - Use radsort for Transparent2d PhaseItem sorting
- Automatic batching/instancing of draw commands
- Directly copy data into uniform buffers
- Allow other plugins to create renderer resources
- Use EntityHashMap<Entity, T> for render world entity storage for better performance
- Parallelize extract_meshes
- Fix comment grammar
- Allow overriding global wireframe setting.
- wireframes: workaround for DX12
- Alternate wireframe override api
- Fix TextureAtlasBuilder padding
- fix example mesh2d_manual
- PCF For DirectionalLight/SpotLight Shadows
- Refactor the render instance logic in #9903 so that it's easier for other components to adopt.
- Fix 2d_shapes and general 2D mesh instancing
- fix webgl2 crash
- fix orthographic cluster aabb for spotlight culling
- Add consuming builder methods for more ergonomic
Meshcreation - wgpu 0.17
- use
Materialfor wireframes - Extract common wireframe filters in type alias
- Deferred Renderer
- Configurable colors for wireframe
- chore: Renamed RenderInstance trait to ExtractInstance
- pbr shader cleanup
- Fix text2d view-visibility
- Allow optional extraction of resources from the main world
- ssao use unlit_color instead of white
- Fix missing explicit lifetime name for copy_deferred_lighting_id name
- Fixed mod.rs in rendering to support Radeon Cards
- Explain usage of prepass shaders in docs for
Materialtrait - Better link for prepare_windows docs
- Improve linking within
RenderSetdocs. - Fix unlit missing parameters
*_PREPASSShader Def Cleanup- check for any prepass phase
- allow extensions to StandardMaterial
- array_texture example: use new name of pbr function
- chore: use ExtractComponent derive macro for EnvironmentMapLight and FogSettings
- Variable
MeshPipelineView Bind Group Layout - update shader imports
- Bind group entries
- Detect cubemap for dds textures
- Fix alignment on ios simulator
- Add convenient methods for Image
- Use “specular occlusion” term to consistently extinguish fresnel on Ambient and Environment Map lights
- Fix fog color being inaccurate
- Replace all usages of texture_descritor.size.* with the helper methods
- View Transformations
- fix deferred example fog values
- WebGL2: fix import path for unpack_unorm3x4_plus_unorm_20_
- Use wildcard imports in bevy_pbr
- Make mesh attr vertex count mismatch warn more readable
- Image Sampler Improvements
- Fix sampling of diffuse env map texture with non-uniform control flow
- Log a warning when the
tonemapping_lutsfeature is disabled but required for the selected tonemapper. - Smaller TAA fixes
- Truncate attribute buffer data rather than attribute buffers
- Fix deferred lighting pass values not all working on M1 in WebGL2
- Add frustum to shader View
- Fix handling of
double_sidedfor normal maps - Add helper function to determine if color is transparent
StandardMaterialLight Transmission- double sided normals: fix apply_normal_mapping calls
- Combine visibility queries in check_visibility_system
- Make VERTEX_COLORS usable in prepass shader, if available
- allow DeferredPrepass to work without other prepass markers
- Increase default normal bias to avoid common artifacts
- Make
DirectionalLightCascadescomputation generic overCameraProjection - Update default
ClearColorto better match Bevy's branding - Fix gizmo crash when prepass enabled
A-Build-System + A-Meta #
A-Assets #
- doc(asset): fix asset trait example
- Add
GltfLoader::new. - impl
From<&AssetPath>forHandleId - allow asset loader pre-registration
- fix asset loader preregistration for multiple assets
- Fix point light radius
- Add support for KHR_materials_emissive_strength
- Fix panic when using
.load_folder()with absolute paths - Bevy Asset V2
- create imported asset directory if needed
- Copy on Write AssetPaths
- Asset v2: Asset path serialization fix
- don't ignore some EventKind::Modify
- Manual "Reflect Value" AssetPath impl to fix dynamic linking
- Fix unused variable warning for simple AssetV2 derives
- Remove monkey.gltf
- Update notify-debouncer-full requirement from 0.2.0 to 0.3.1
- Removed
anyhow - Multiple Asset Sources
- Make loading warning for no file ext more descriptive
- Fix load_folder for non-default Asset Sources
- only set up processed source if asset plugin is not unprocessed
- Hot reload labeled assets whose source asset is not loaded
- Return an error when loading non-existent labels
- remove unused import on android
- Log an error when registering an AssetSource after AssetPlugin has been built
- Add note about asset source register order
- Add
asset_processorfeature and remove AssetMode::ProcessedDev - Implement source into Display for AssetPath
- assets: use blake3 instead of md5
- Reduce noise in asset processing example
- Adding AssetPath::resolve() method.
- Assets: fix first hot reloading
- Non-blocking load_untyped using a wrapper asset
- Reuse and hot reload folder handles
- Additional AssetPath unit tests.
- Corrected incorrect doc comment on read_asset_bytes
- support file operations in single threaded context