

Bevy 0.5
Posted on April 6, 2021 by Carter Anderson (  @cart
@cart  cartdev )
cartdev )

Thanks to 88 contributors, 283 pull requests, and our generous sponsors, I'm happy to announce the Bevy 0.5 release on crates.io!
For those who don't know, Bevy is a refreshingly simple data-driven game engine built in Rust. You can check out The Quick Start Guide to get started. Bevy is also free and open source forever! You can grab the full source code on GitHub. Check out Awesome Bevy for a list of community-developed plugins, games, and learning resources.
Bevy 0.5 is quite a bit bigger than our past few releases (and took a bit longer) as we have made a number of foundational changes. If you plan on updating your App or Plugin to Bevy 0.5, check out our 0.4 to 0.5 Migration Guide.
Here are some of the highlights from this release:
Physically Based Rendering (PBR) #
Bevy now uses PBR shaders when rendering. PBR is a semi-standard approach to rendering that attempts to use approximations of real-world "physically based" lighting and material properties. We largely use techniques from the Filament PBR implementation, but we also incorporate some ideas from Unreal and Disney.
Bevy's StandardMaterial now has base_color, roughness, metallic, reflection, and emissive properties. It also now supports textures for base_color, normal_map, metallic_roughness, emissive, and occlusion properties.
The new PBR example helps visualize these new material properties:

GLTF Improvements #
PBR Textures #
The GLTF loader now supports normal maps, metallic/roughness, occlusion, and emissive textures. Our "flight helmet" gltf example utilizes the new PBR texture support and looks much nicer as a result:
Top-Level GLTF Asset #
Previously it was hard to interact with GLTF assets because scenes / meshes / textures / and materials were only loaded as "sub assets". Thanks to the new top level Gltf asset type, it is now possible to navigate the contents of the GLTF asset:
// load GLTF asset on startup
// access GLTF asset at some later point in time
Bevy ECS V2 #
This release marks a huge step forward for Bevy's ECS. It has significant implications for how Bevy Apps are composed and how well they perform:
- A full rewrite of the ECS core:
- Massively improved performance across the board
- "Hybrid" component storage
- An "Archetype Graph" for faster archetype changes
- Stateful queries that cache results across runs
- A brand new parallel System executor:
- Support for explicit system ordering
- System Labels
- System Sets
- Improved system "run criteria"
- Increased system parallelism
- "Reliable" change detection:
- Systems will now always detect component changes, even across frames
- A rewrite of the State system:
- A much more natural "stack-based state machine" model
- Direct integration with the new scheduler
- Improved "state lifecycle" events
Read on for the details!
ECS Core Rewrite #
Up until this point, Bevy used a heavily forked version of hecs for our ECS core. Since Bevy's first release, we've learned a lot about Bevy's ECS needs. We've also collaborated with other ECS project leaders, such as Sander Mertens (lead flecs developer) and Gijs-Jan Roelofs (Xenonauts ECS framework developer). As an "ECS community", we've started to zero in on what the future of ECS could be.
Bevy ECS v2 is our first step into that future. It also means that Bevy ECS is no longer a "hecs fork". We are going out on our own!
Component Storage (The Problem) #
Two ECS storage paradigms have gained a lot of traction over the years:
- Archetypal ECS:
- Stores components in "tables" with static schemas. Each "column" stores components of a given type. Each "row" is an entity.
- Each "archetype" has its own table. Adding/removing an entity's component changes the archetype.
- Enables super-fast Query iteration due to its cache-friendly data layout
- Comes at the cost of more expensive add/remove operations for an Entity's components, because all components need to be copied to the new archetype's "table"
- Parallelism-friendly: entities only exist in one archetype at a time so systems that access the same components but in different archetypes can run in parallel
- Frameworks: Old Bevy ECS, hecs, legion, flecs, Unity DOTS
- Sparse Set ECS:
- Stores components of the same type in densely packed arrays, which are sparsely indexed by densely packed unsigned integers (entity ids)
- Query iteration is slower than Archetypal ECS (by default) because each entity's component could be at any position in the sparse set. This "random access" pattern isn't cache friendly. Additionally, there is an extra layer of indirection because you must first map the entity id to an index in the component array.
- Adding/removing components is a cheap, constant time operation
- "Component Packs" are used to optimize iteration performance on a case by case basis (but packs conflict with each other)
- Less parallelism friendly: systems need to either lock a whole component storage (not granular) or individual entities (expensive)
- Frameworks: Shipyard, EnTT
Developers selecting an ECS framework are stuck with a hard choice. Select an "archetypal" framework with "fast iteration everywhere" but without the ability to cheaply add/remove components, or select a "sparse set" framework to cheaply add/remove components but with slower iteration performance or manual (and conflicting) pack optimizations.
Hybrid Component Storage (The Solution) #
In Bevy ECS V2, we get to have our cake and eat it too. It now has both of the component storage types above (and more can be added later if needed):
- Tables (aka "archetypal" storage in other frameworks)
- The default storage. If you don't configure anything, this is what you get
- Fast iteration by default
- Slower add/remove operations
- Sparse Sets
- Opt-in
- Slower iteration
- Faster add/remove operations
These storage types complement each other perfectly. By default Query iteration is fast. If developers know that they want to add/remove a component at high frequencies, they can set the storage to "sparse set":
app.register_component;
Component Add/Remove Benchmark (in milliseconds, less is better) #
This benchmark illustrates adding and removing a single 4x4 matrix component 10,000 times from an entity that has 5 other 4x4 matrix components. The "other" components are included to help illustrate the cost of "table storage" (used by Bevy 0.4, Bevy 0.5 (Table), and Legion), which requires moving the "other" components to a new table.

You may have noticed that Bevy 0.5 (Table) is also way faster than Bevy 0.4, even though they both use "table storage". This is largely a result of the new Archetype Graph, which significantly cuts the cost of archetype changes.
Stateful Queries and System Parameters #
World queries (and other system parameters) are now stateful. This allows us to:
- Cache archetype (and table) matches
- This resolves another issue with (naive) archetypal ECS: query performance getting worse as the number of archetypes goes up (and fragmentation occurs).
- Cache Query Fetch and Filter state
- The expensive parts of fetch/filter operations (such as hashing the TypeId to find the ComponentId) now only happen once when the Query is first constructed
- Incrementally build up state
- When new archetypes are added, we only process the new archetypes (no need to rebuild state for old archetypes)
As a result, the direct World query API now looks like this:
let mut query = world.;
for in query.iter_mut
However for systems this is a non-breaking change. Query state management is done internally by the relevant SystemParam.
We have achieved some pretty significant performance wins as a result of the new [Query] system.
"Sparse" Fragmented Iterator Benchmark (in nanoseconds, less is better) #
This benchmark runs a query that matches 5 entities within a single archetype and doesn't match 100 other archetypes. This is a reasonable test of "real world" queries in games, which generally have many different entity "types", most of which don't match a given query. This test uses "table storage" across the board.

Bevy 0.5 marks a huge improvement for cases like this, thanks to the new "stateful queries". Bevy 0.4 needs to check every archetype each time the iterator is run, whereas Bevy 0.5 amortizes that cost to zero.
Fragmented Iterator Benchmark (in milliseconds, less is better) #
This is the ecs_bench_suite frag_iter benchmark. It runs a query on 27 archetypes with 20 entities each. However unlike the "Sparse Fragmented Iterator Benchmark", there are no "unmatched" archetypes. This test uses "table storage" across the board.

The gains here compared to the last benchmark are smaller because there aren't any unmatched archetypes. However Bevy 0.5 still gets a nice boost due to better iterator/query impls, amortizing the cost of matched archetypes to zero, and for_each iterators.
Uber Fast "for_each" Query Iterators #
Developers now have the choice to use a fast Query::for_each iterator, which yields ~1.5-3x iteration speed improvements for "fragmented iteration", and minor ~1.2x iteration speed improvements for unfragmented iteration.
We will continue to encourage "normal" iterators as they are more flexible and more "rust idiomatic". But when that extra "oomf" is needed, for_each will be there ... waiting for you :)
New Parallel System Executor #
Bevy's old parallel executor had a number of fundamental limitations:
- The only way to explicitly define system order was to create new stages. This was both boilerplate-ey and prevented parallelism (because stages run "one by one" in order). We've noticed that system ordering is a common requirement and stages just weren't cutting it.
- Systems had "implicit" orderings when they accessed conflicting resources. These orderings were hard to reason about.
- The "implicit orderings" produced execution strategies that often left a lot of parallelism potential on the table.
Fortunately @Ratysz has been doing a lot of research in this area and volunteered to contribute a new executor. The new executor solves all of the issues above and also adds a bunch of new usability improvements. The "ordering" rules are now dead-simple:
- Systems run in parallel by default
- Systems with explicit orderings defined will respect those orderings
Explicit System Dependencies and System Labels #
Systems can now be assigned one or more SystemLabels. These labels can then be referenced by other systems (within a stage) to run before or after systems with that label:
app
.add_system
// The "movement" system will run after "update_velocity"
.add_system
This produces an equivalent ordering, but it uses before() instead.
app
// The "update_velocity" system will run before "movement"
.add_system
.add_system;
Any type that implements the SystemLabel trait can be used. In most cases we recommend defining custom types and deriving SystemLabel for them. This prevents typos, allows for encapsulation (when needed), and allows IDEs to autocomplete labels:
app
.add_system
.add_system;
Many-to-Many System Labels #
Many-to-many labels is a powerful concept that makes it easy to take a dependency on many systems that produce a given behavior/outcome. For example, if you have a system that needs to run after all "physics" has finished updating (see the example above), you could label all "physics systems" with the same Physics label:
;
app
.add_system
.add_system
.add_system;
Bevy plugin authors should export labels like this in their public APIs to enable their users to insert systems before/after logic provided by the plugin.
System Sets #
SystemSets are a new way to apply the same configuration to a group of systems, which significantly cuts down on boilerplate. The "physics" example above could be rephrased like this:
app
.add_system_set
SystemSets can also use before(Label) and after(Label) to run all systems in the set before/after the given label.
This is also very useful for groups of systems that need to run with the same RunCriteria.
app
// all systems in this set will run once every two seconds
.add_system_set
Improved Run Criteria #
Run Criteria are now decoupled from systems and will be re-used when possible. For example, the FixedTimestep criteria in the example above will only be run once per stage run. The executor will re-use the criteria's result for both the foo and bar system.
Run Criteria can now also be labeled and referenced by other systems:
app.add_stage
.add_system
Results from Run Criteria can also be "piped" into other criteria, which enables interesting composed behaviors:
app
.add_systemAmbiguity Detection and Resolution #
While the new executor is now much easier to reason about, it does introduce a new class of error: "system order ambiguities". When two systems interact with the same data, but have no explicit ordering defined, the output they produce is non-deterministic (and often not what the author intended).
Consider the following app:
app
.add_system
.add_system
The author clearly intended print_every_other_time to run every other update. However, due to the fact that these systems have no order defined, they could run in a different order each update and create a situation where nothing is printed over the course of two updates:
UPDATE
- increment_counter (counter now equals 1)
- print_every_other_time (nothing printed)
UPDATE
- print_every_other_time (nothing printed)
- increment_counter (counter now equals 2)
The old executor would have implicitly forced increment_counter to run first because it conflicts with print_every_other_time and it was inserted first. But the new executor requires you to be explicit here (which we believe is a good thing).
To help detect this class of error, we built an opt-in tool that detects these ambiguities and logs them:
// add this resource to your App to enable ambiguity detection
app.insert_resource
Then when we run our App, we will see the following message printed to our terminal:
Execution order ambiguities detected, you might want to add an explicit dependency relation between some of these systems:
* Parallel systems:
-- "&app::increment_counter" and "&app::print_every_other_time"
conflicts: ["usize"]
The ambiguity detector found a conflict and mentions that adding an explicit dependency would resolve the conflict:
app
.add_system
.add_system
There are some cases where ambiguities are not a bug, such as operations on unordered collection like Assets. This is why we don't enable the detector by default. You are free to just ignore these ambiguities, but if you want to suppress the messages in the detector (without defining a dependency), you can add your systems to an "ambiguity set":
app
.add_system
.add_system
I want to stress that this is totally optional. Bevy code should be ergonomic and "fun" to write. If sprinkling ambiguity sets everywhere isn't your cup of tea, just don't worry about it!
We are also actively seeking feedback on the new executor. We believe that the new implementation is easier to understand and encourages self-documenting code. The improved parallelism is also nice! But we want to hear from users (both new users starting fresh and old users porting their codebases to the new executor). This space is all about design tradeoffs and feedback will help us ensure we made the right calls.
Reliable change detection #
Global change detection, the ability to run queries on the Changed/Added status of any ECS component or resource, just got a major usability boost: changes are now detected across frames/updates:
// This is still the same change detection API we all know and love,
// the only difference is that it "just works" in every situation.
Global change detection was already a feature that set Bevy apart from other ECS frameworks, but now it is completely "fool proof". It works as expected regardless of system ordering, stage membership, or system run criteria.
The old behavior was "systems detect changes that occurred in systems that ran before them this frame". This was because we used a bool to track when each component/resource is added/modified. This flag was cleared for each component at the end of the frame. As a result, users had to be very careful about order of operations, and using features like "system run criteria" could result in dropped changes if systems didn't run on a given update.
We now use a clever "world tick" design that allows systems to detect changes that happened at any point in time since their last run.
States V2 #
The last Bevy release added States, which enabled developers to run groups of ECS systems according to the value of a State<T> resource. Systems could be run according to "state lifecycle events", such as on_enter, on_update, and on_exit. States make things like separate "loading screen" and "in game" logic easier to encode in Bevy ECS.
The old implementation largely worked, but it had a number of quirks and limitations. First and foremost, it required adding a new StateStage, which cut down on parallelism, increased boilerplate, and forced ordering where it wasn't required. Additionally, some of the lifecycle events didn't always behave as expected.
The new State implementation is built on top of the new parallel executor's SystemSet and RunCriteria features, for a much more natural, flexible, and parallel API that builds on existing concepts instead of creating new ones:
States now use a "stack-based state machine" model. This opens up a number of options for state transitions:
Just like the old implementation, state changes are applied in the same frame. This means it is possible to transition from states A->B->C and run the relevant state lifecycle events without skipping frames. This builds on top of "looping run criteria", which we also use for our "fixed timestep" implementation (and which you can use for your own run criteria logic).
Event Ergonomics #
Events now have a first-class shorthand syntax for easier consumption:
// Old Bevy 0.4 syntax
// New Bevy 0.5 syntax
There is also now a symmetrical EventWriter API:
The old "manual" approach is still possible via ManualEventReader:
Rich Text #
Text can now have "sections", each with their own style / formatting. This makes text much more flexible, while still respecting the text layout rules:

This is accomplished using the new "text section" API:
commands
.spawn_bundle
HIDPI Text #
Text is now rendered according to the current monitor's scale factor. This gives nice, crisp text at any resolution.
Render Text in 2D World Space #
Text can now be spawned into 2D scenes using the new Text2dBundle. This makes it easier to do things like "draw names above players".
World To Screen Coordinate Conversions #
It is now possible to convert world coordinates to a given camera's screen coordinates using the new Camera::world_to_screen() function. Here is an example of this feature being used to position a UI element on top of a moving 3d object.
3D Orthographic Camera #
Orthographic cameras can now be used in 3D! This is useful for things like CAD applications and isometric games.
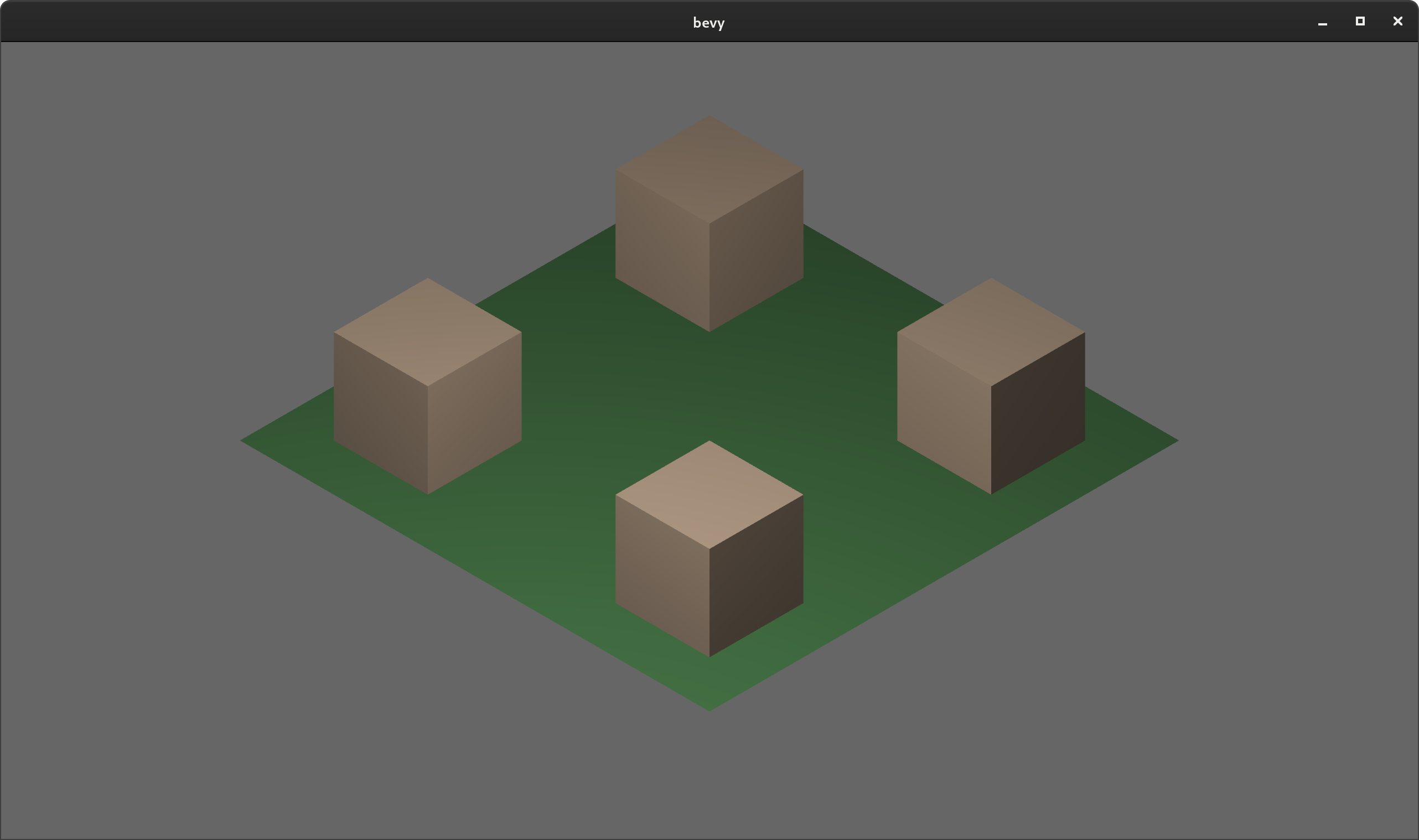
Orthographic Camera Scaling Modes #
Prior to Bevy 0.5, Bevy's orthographic camera had only one mode: "window scaling". It would adapt the projection according to the vertical and horizontal size of the window. This works for some styles of games, but other games need arbitrary window-independent scale factors or scale factors defined by either horizontal or vertical window sizes.
Bevy 0.5 adds a new ScalingMode option to OrthographicCamera, which enables developers to customize how the projection is calculated.
It also adds the ability to "zoom" the camera using OrthographicProjection::scale.
Flexible Camera Bindings #
Bevy used to "hack in" camera bindings for each RenderGraph PassNode. This worked when there was only one binding type (the combined ViewProj matrix), but many shaders require other camera properties, such as the world space position.
In Bevy 0.5 we removed the "hack" in favor of the RenderResourceBindings system used elsewhere. This enables shaders to bind arbitrary camera data (with any set or binding index) and only pull in the data they need.
The new PBR shaders take advantage of this feature, but custom shaders can also use it.
layout uniform CameraViewProj ;
layout uniform CameraPosition ;
Render Layers #
Sometimes you don't want a camera to draw everything in a scene, or you want to temporarily hide a set of things in the scene. Bevy 0.5 adds a RenderLayer system, which gives developers the ability to add entities to layers by adding the RenderLayers component.
Cameras can also have a RenderLayers component, which determines what layers they can see.
// spawn a sprite on layer 0
commands
.spawn_bundle
.insert;
// spawn a sprite on layer 1
commands
.spawn_bundle
.insert;
// spawn a camera that only draws the sprite on layer 1
commands
.spawn_bundle;
.insert;
Sprite Flipping #
Sprites can now be easily (and efficiently) flipped along the x or y axis:
![]()
commands.spawn_bundle;
commands.spawn_bundle;
Color Spaces #
Color is now internally represented as an enum, which enables lossless (and correct) color representation. This is a significant improvement over the previous implementation, which internally converted all colors to linear sRGB (which could cause precision issues). Colors are now only converted to linear sRGB when they are sent to the GPU. We also took this opportunity to fix some incorrect color constants defined in the wrong color space.
Wireframes #
Bevy can now draw wireframes using the opt-in WireframePlugin
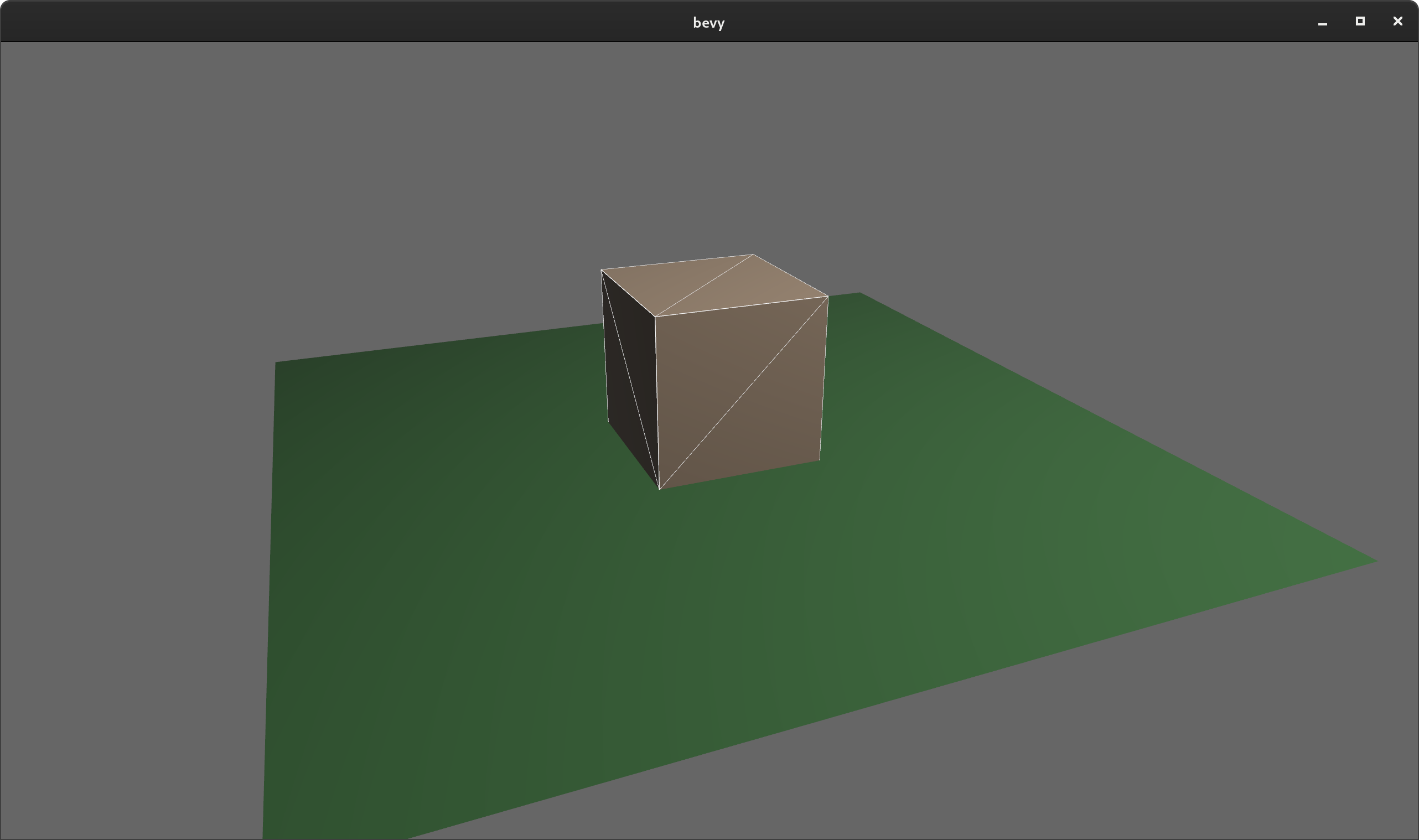
These can either be enabled globally or per-entity by adding the new Wireframe component.
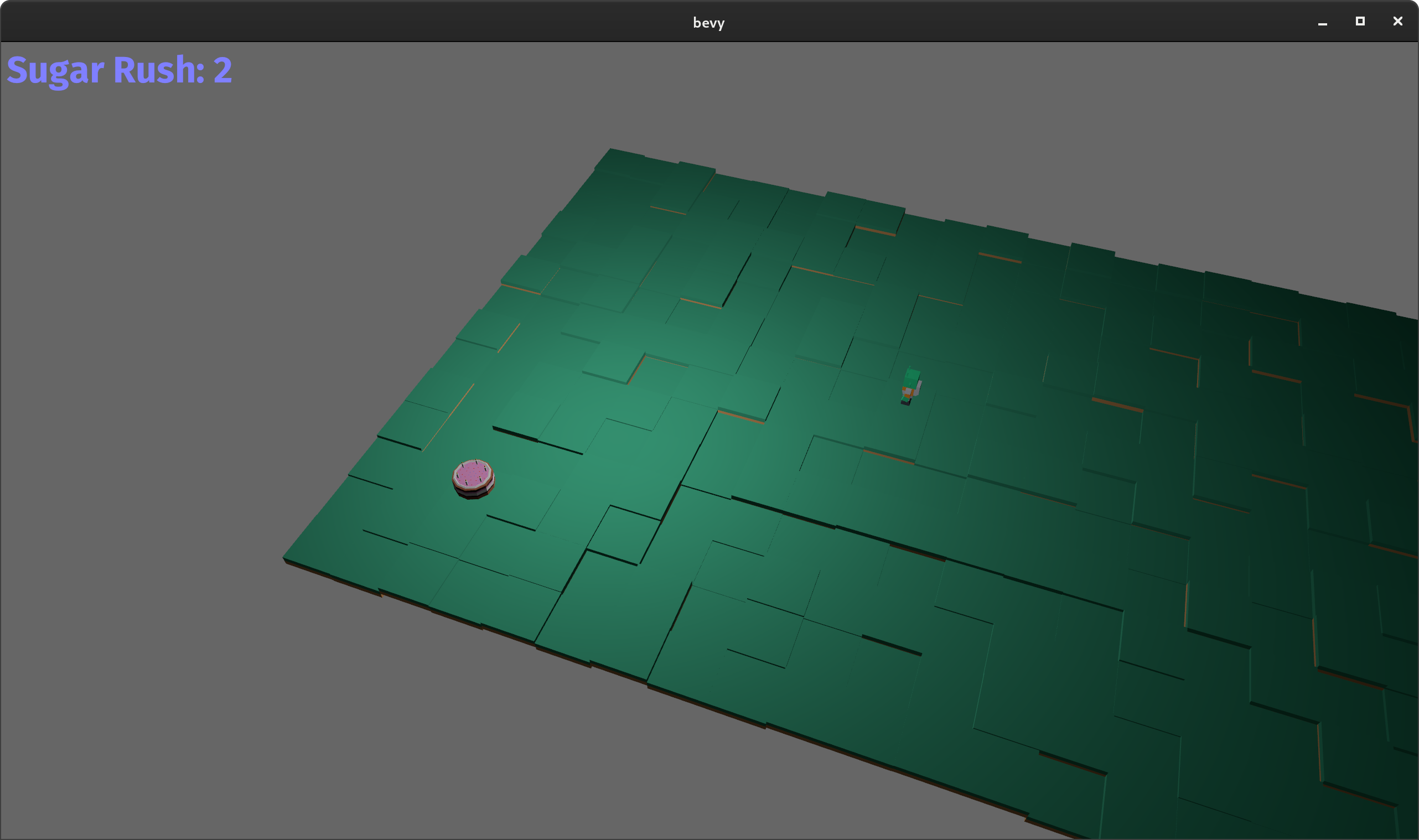
Simple 3D Game Example: Alien Cake Addict #
This example serves as a quick introduction to building 3D games in Bevy. It shows how to spawn scenes, respond to input, implement game logic, and handle state transitions. Pick up as many cakes as you can!
Timer Improvements #
The Timer struct now internally uses Duration instead of using f32 representations of seconds. This both increases precision and makes the API a bit nicer to look at.
Assets Improvements #
Bevy's asset system had a few minor improvements this release:
- Bevy no longer panics on errors when loading assets
- Asset paths with multiple dots are now properly handled
- Improved type safety for "labeled assets" produced by asset loaders
- Made asset path loading case-insensitive
WGPU Configuration Options #
It is now possible to enable/disable wgpu features (such as WgpuFeature::PushConstants and WgpuFeature::NonFillPolygonMode) by setting them in the WgpuOptions resource:
app
.insert_resource
Wgpu limits (such as WgpuLimits::max_bind_groups) can also now be configured in the WgpuOptions resource.
Scene Instance Entity Iteration #
It is now possible to iterate all entities in a spawned scene instance. This makes it possible to perform post-processing on scenes after they have been loaded.
;
Window Resize Constraints #
Windows can now have "resize constraints". Windows cannot be resized past these constraints
app
.insert_resource
!Send Tasks #
Bevy's async task system now supports !Send tasks. Some tasks cannot be sent / run on other threads (such as tasks created by the upcoming Distill asset plugin). "Thread local" tasks can now be spawned in Bevy TaskPools like this:
let pool = default;
pool.scope;
More ECS V2 Changes #
EntityRef / EntityMut #
World entity operations in Bevy 0.4 require that the user passes in an entity id to each operation:
let entity = world.spawn; // create a new entity with A
world.;
world.insert;
world.insert_one;
This means that each operation needs to look up the entity location / verify its validity. The initial spawn operation also requires a Bundle as input. This can be awkward when no components are required (or one component is required).
These operations have been replaced by EntityRef and EntityMut, which are "builder-style" wrappers around world that provide read and read/write operations on a single, pre-validated entity:
// spawn now takes no inputs and returns an EntityMut
let entity = world.spawn
.insert // insert a single component into the entity
.insert_bundle // insert a bundle of components into the entity
.id // id returns the Entity id
// Returns EntityMut (or panics if the entity does not exist)
world.entity_mut
.insert
.insert_bundle;
// The `get_X` variants return Options, in case you want to check existence instead of panicking
world.get_entity_mut
.unwrap
.insert;
if let Some = world.get_entity
Commands have also been updated to use this new pattern
let entity = commands.spawn
.insert
.insert_bundle
.insert_bundle
.id;
Commands also still support spawning with a Bundle, which should make migration from Bevy 0.4 easier. It also cuts down on boilerplate in some situations:
commands.spawn_bundle;
Note that these Command methods use the "type state" pattern, which means this style of chaining is no longer possible:
// Spawns two entities, each with the components in SomeBundle and the A component
// Valid in Bevy 0.4, but invalid in Bevy 0.5
commands
.spawn
.insert
.spawn
.insert;
Instead, you should do this:
commands
.spawn_bundle
.insert;
commands
.spawn_bundle
.insert;
This allows us to make things like "entity id retrieval" infallible and opens the doors to future API improvements.
Query::single #
Queries now have Query::single and Query::single_mut methods, which return a single query result if there is exactly one matching entity:
Removed ChangedRes #
We have removed ChangedRes<A> in favor of the following:
Optional Resource Queries #
It is now possible for a system to check for Resource existence via Option queries:
New Bundle Naming Convention #
Component Bundles previously used the XComponents naming convention (ex: SpriteComponents, TextComponents, etc). We decided to move to a XBundle naming convention (ex: SpriteBundle, TextBundle, etc) to be more explicit about what these types are and to help prevent new users from conflating Bundles and Components.
World Metadata Improvements #
World now has queryable Components, Archetypes, Bundles, and Entities collections:
// you can access these new collections from normal systems, just like any other SystemParam
This enables developers to access internal ECS metadata from their Systems.
Configurable SystemParams #
Users can now provide some initial configuration / values for system parameters (when possible). Most SystemParams have no config (the config type is ()), but the Local<T> param now supports user-provided parameters:
app.add_system;
Preparation for Scripting Support #
Bevy ECS Components are now decoupled from Rust types. The new Components collection stores metadata such as memory layout and destructors. Components also no longer require Rust TypeIds.
New component metadata can be added at any time using world.register_component().
All component storage types (currently Table and Sparse Set) are "blob storage". They can store any value with a given memory layout. This enables data from other sources (ex: a Python data type) to be stored and accessed in the same way as Rust data types.
We haven't completely enabled scripting yet (and will likely never officially support non-Rust scripting), but this is a major step toward enabling community-supported scripting languages.
Merged Resources into World #
Resources are now just a special kind of Component. This allows us to keep the code size small by reusing existing Bevy ECS internals. It also enabled us to optimize the parallel executor access controls and it should make scripting language integration easier down the line.
world.insert_resource;
world.insert_resource;
let a = world..unwrap;
let mut b = world..unwrap;
*b = 3.0;
// Resources are still accessed the same way in Systems
But this merge did create problems for people directly interacting with World. What if you need mutable access to multiple resources at the same time? world.get_resource_mut() borrows World mutably, which prevents multiple mutable accesses! We solved this with WorldCell.
WorldCell #
WorldCell applies the "access control" concept used by Systems to direct world access:
let world_cell = world.cell;
let a = world_cell..unwrap;
let b = world_cell..unwrap;
This adds cheap runtime checks to ensure that world accesses do not conflict with each other.
We made this a separate API to enable users to decide what tradeoffs they want. Direct World access has stricter lifetimes, but it is more efficient and does compile time access control. WorldCell has looser lifetimes, but incurs a small runtime penalty as a result.
The API is currently limited to resource access, but it will be extended to queries / entity component access in the future.
Resource Scopes #
WorldCell does not yet support component queries, and even when it does there will sometimes be legitimate reasons to want a mutable world ref and a mutable resource ref (ex: bevy_render and bevy_scene both need this). In these cases we could always drop down to the unsafe world.get_resource_unchecked_mut(), but that is not ideal!
Instead developers can use a "resource scope"
world.resource_scope
This temporarily removes the A resource from World, provides mutable pointers to both, and re-adds A to World when finished. Thanks to the move to ComponentIds/sparse sets, this is a cheap operation.
If multiple resources are required, scopes can be nested. We could also consider adding a "resource tuple" to the API if this pattern becomes common and the boilerplate gets nasty.
Query Conflicts Use ComponentId Instead of ArchetypeComponentId #
For safety reasons, systems cannot contain queries that conflict with each other without wrapping them in a QuerySet. In Bevy 0.4, we used ArchetypeComponentIds to determine conflicts. This was nice because it could take into account filters:
// these queries will never conflict due to their filters
But it also had a significant downside:
// these queries will not conflict _until_ an entity with A, B, and C is spawned
The system above will panic at runtime if an entity with A, B, and C is spawned. This makes it hard to trust that your game logic will run without crashing.
In Bevy 0.5, we switched to using ComponentId instead of ArchetypeComponentId. This is more constraining. maybe_conflicts_system will now always fail, but it will do it consistently at startup.
Naively, it would also disallow filter_system, which would be a significant downgrade in usability. Bevy has a number of internal systems that rely on disjoint queries and we expect it to be a common pattern in userspace. To resolve this, we added a new internal FilteredAccess<T> type, which wraps Access<T> and adds with/without filters. If two FilteredAccess have with/without values that prove they are disjoint, they will no longer conflict.
This means filter_system is still perfectly valid in Bevy 0.5. We get most of the benefits of the old implementation, but with consistent and predictable rules enforced at app startup.
What's Next For Bevy? #
We still have a long road ahead of us, but the Bevy developer community is growing at a rapid pace and we already have big plans for the future. Expect to see progress in the following areas soon:
- "Pipelined" rendering and other renderer optimizations
- Bevy UI redesign
- Animation: component animation and 3d skeletal animation
- ECS: relationships/indexing, async systems, archetype invariants, "stageless" system schedules
- 3D Lighting Features: shadows, more light types
- More Bevy Scene features and usability improvements
We also plan on breaking ground on the Bevy Editor as soon as we converge on a final Bevy UI design.
Support Bevy #
Sponsorships help make full time work on Bevy sustainable. If you believe in Bevy's mission, consider sponsoring @cart ... every bit helps!
Contributors #
A huge thanks to the 88 contributors that made this release (and associated docs) possible!
- mockersf
- CAD97
- willcrichton
- Toniman20
- ElArtista
- lassade
- Divoolej
- msklywenn
- cart
- maxwellodri
- schell
- payload
- guimcaballero
- themilkybit
- Davier
- TheRawMeatball
- alexschrod
- Ixentus
- undinococo
- zicklag
- lambdagolem
- reidbhuntley
- enfipy
- CleanCut
- LukeDowell
- IngmarBitter
- MinerSebas
- ColonisationCaptain
- tigregalis
- siler
- Lythenas
- Restioson
- kokounet
- ryanleecode
- adam-bates
- Neo-Zhixing
- bgourlie
- Telzhaak
- rkr35
- jamadazi
- bjorn3
- VasanthakumarV
- turboMaCk
- YohDeadfall
- rmsc
- szunami
- mnmaita
- WilliamTCarroll
- Ratysz
- OptimisticPeach
- mtsr
- AngelicosPhosphoros
- Adamaq01
- Moxinilian
- tomekr
- jakobhellermann
- sdfgeoff
- Byteron
- aevyrie
- verzuz
- ndarilek
- huhlig
- zaszi
- Puciek
- DJMcNab
- sburris0
- rparrett
- smokku
- TehPers
- alec-deason
- Fishrock123
- woubuc
- Newbytee
- Archina
- StarArawn
- JCapucho
- M2WZ
- TotalKrill
- refnil
- bitshifter
- NiklasEi
- alice-i-cecile
- joshuajbouw
- DivineGod
- ShadowMitia
- memoryruins
- blunted2night
- RedlineTriad
Change Log #
Added #
- PBR Rendering
- PBR Textures
- HIDPI Text
- Rich text
- Wireframe Rendering Pipeline
- Render Layers
- Add Sprite Flipping
- OrthographicProjection scaling mode + camera bundle refactoring
- 3D OrthographicProjection improvements + new example
- Flexible camera bindings
- Render text in 2D scenes
- Text2d render quality
- System sets and run criteria v2
- System sets and parallel executor v2
- Many-to-many system labels
- Non-string labels (#1423 continued)
- Make EventReader a SystemParam
- Add EventWriter
- Reliable change detection
- Redo State architecture
- Query::get_unique
- gltf: load normal and occlusion as linear textures
- Add separate brightness field to AmbientLight
- world coords to screen space
- Experimental Frustum Culling (for Sprites)
- Enable wgpu device limits
- bevy_render: add torus and capsule shape
- New mesh attribute: color
- Minimal change to support instanced rendering
- Add support for reading from mapped buffers
- Texture atlas format and conversion
- enable wgpu device features
- Subpixel text positioning
- make more information available from loaded GLTF model
- use Name on node when loading a gltf file
- GLTF loader: support mipmap filters
- Add support for gltf::Material::unlit
- Implement Reflect for tuples up to length 12
- Process Asset File Extensions With Multiple Dots
- Update Scene Example to Use scn.ron File
- 3d game example
- Add keyboard modifier example (#1656)
- Count number of times a repeating Timer wraps around in a tick
- recycle
Timerrefactor to duration.sparkles AddStopwatchstruct. - add scene instance entity iteration
- Make Commands and World apis consistent
- Add
insert_childrenandpush_childrento EntityMut - Extend AppBuilder API with
add_system_setand similar methods - add labels and ordering for transform and parent systems in POST_UPDATE stage
- Explicit execution order ambiguities API
- Resolve (most) internal system ambiguities
- Change 'components' to 'bundles' where it makes sense semantically
- add
Flags<T>as a query to get flags of component - Rename add_resource to insert_resource
- Update init_resource to not overwrite
- Enable dynamic mutable access to component data
- Get rid of ChangedRes
- impl SystemParam for Option<Res
> / Option<ResMut > - Add Window Resize Constraints
- Add basic file drag and drop support
- Modify Derive to allow unit structs for RenderResources.
- bevy_render: load .spv assets
- Expose wgpu backend in WgpuOptions and allow it to be configured from the environment
- updates on diagnostics (log + new diagnostics)
- enable change detection for labels
- Name component with fast comparisons
- Support for !Send tasks
- Add missing spawn_local method to Scope in the single threaded executor case
- Add bmp as a supported texture format
- Add an alternative winit runner that can be started when not on the main thread
- Added use_dpi setting to WindowDescriptor
- Implement Copy for ElementState
- Mutable mesh accessors: indices_mut and attribute_mut
- Add support for OTF fonts
- Add
from_xyztoTransform- Adding copy_texture_to_buffer and copy_texture_to_texture
- Added
set_minimizedandset_positiontoWindow- Example for 2D Frustum Culling
- Add remove resource to commands
Changed #
- Bevy ECS V2
- Fix Reflect serialization of tuple structs
- color spaces and representation
- Make vertex buffers optional
- add to lower case to make asset loading case insensitive
- Replace right/up/forward and counter parts with local_x/local_y and local_z
- Use valid keys to initialize AHasher in FixedState
- Change Name to take Into
instead of String - Update to wgpu-rs 0.7
- Update glam to 0.13.0.
- use std clamp instead of Bevy's
- Make Reflect impls unsafe (Reflect::any must return
self)Fixed #
- convert grayscale images to rgb
- Glb textures should use bevy_render to load images
- Don't panic on error when loading assets
- Prevent ImageBundles from causing constant layout recalculations
- do not check for focus until cursor position has been set
- Fix lock order to remove the chance of deadlock
- Prevent double panic in the Drop of TaksPoolInner
- Ignore events when receiving unknown WindowId
- Fix potential bug when using multiple lights.
- remove panics when mixing UI and non UI entities in hierarchy
- fix label to load gltf scene
- fix repeated gamepad events
- Fix iOS touch location
- Don't panic if there's no index buffer and call draw
- Fix Bug in Asset Server Error Message Formatter
- add_stage now checks Stage existence
- Fix Un-Renamed add_resource Compile Error
- Fix Interaction not resetting to None sometimes
- Fix regression causing "flipped" sprites to be invisible
- revert default vsync mode to Fifo
- Fix missing paths in ECS SystemParam derive macro
- Fix staging buffer required size calculation (fixes #1056)