

Bevy 0.6
Posted on January 8, 2022 by Carter Anderson (  @cart
@cart  @cart_cart
@cart_cart  cartdev )
cartdev )

Thanks to 170 contributors, 623 pull requests, and our generous sponsors, I'm happy to announce the Bevy 0.6 release on crates.io!
For those who don't know, Bevy is a refreshingly simple data-driven game engine built in Rust. You can check out The Quick Start Guide to get started. Bevy is also free and open source forever! You can grab the full source code on GitHub. Check out Bevy Assets for a collection of community-developed plugins, games, and learning resources.
To update an existing Bevy App or Plugin to Bevy 0.6, check out our 0.5 to 0.6 Migration Guide.
There are a ton of improvements, bug fixes and quality of life tweaks in this release. Here are some of the highlights:
- A brand new modern renderer that is prettier, faster, and simpler to extend
- Directional and point light shadows
- Clustered forward rendering
- Frustum culling
- Significantly faster sprite rendering with less boilerplate
- Native WebGL2 support. You can test this out by running the Bevy Examples in your browser!
- High level custom Materials
- More powerful shaders: preprocessors, imports, WGSL support
- Bevy ECS ergonomics and performance improvements. No more
.system()!
Read on for details!
The New Bevy Renderer #
Bevy 0.6 introduces a brand new modern renderer that is:
- Faster: More parallel, less computation per-entity, more efficient CPU->GPU dataflow, and (with soon-to-be-enabled) pipelined rendering
- Prettier: We're releasing the new renderer alongside a number of graphical improvements, such as directional and point light shadows, clustered forward rendering (so you can draw more lights in a scene), and spherical area lights. We also have a ton of new features in development (cascaded shadow maps, bloom, particles, shadow filters, and more!)
- Simpler: Fewer layers of abstraction, simpler data flow, improved low-level, mid-level, and high-level interfaces, direct wgpu access
- Modular to its core: Standardized 2d and 3d core pipelines, extensible Render Phases and Views, composable entity/component-driven draw functions, shader imports, extensible and repeatable render pipelines via "sub graphs"
- Industry Proven: We've taken inspiration from battle tested renderer architectures, such as Bungie's pipelined Destiny renderer. We also learned a lot from (and worked closely with) other renderer developers in the Rust space, namely @aclysma (rafx) and @cwfitzgerald (rend3). The New Bevy Renderer wouldn't be what it is without them, and I highly recommend checking out their projects!
I promise I'll qualify all of those fluffy buzzwords below. I am confident that the New Bevy Renderer will be a rallying point for the Bevy graphics ecosystem and (hopefully) the Rust graphics ecosystem at large. We still have plenty of work to do, but I'm proud of what we have accomplished so far and I'm excited for the future!

Why build a new renderer? #
Before we cover what's new, it's worth discussing why we embarked on such a massive effort. The old Bevy Renderer got a number of things right:
- Modular render logic (via the Render Graph)
- Multiple backends (both first and third party)
- High level data-driven API: this made it easy and ergonomic to write custom per-entity render logic
However, it also had a number of significant shortcomings:
- Complex: The "high-level ease of use" came at the cost of significant implementation complexity, performance overhead, and invented jargon. Users were often overwhelmed when trying to operate at any level but "high-level". When managing "render resources", it was easy to do something "wrong" and hard to tell "what went wrong".
- Often slow: Features like "sprite rendering" were built on the costly high-level abstractions mentioned above. Performance was ... suboptimal when compared to other options in the ecosystem.
- User-facing internals: It stored a lot of internal render state directly on each entity. This took up space, computing the state was expensive, and it gunked up user-facing APIs with a bunch of "do not touch" render Components. This state (or at least, the component metadata) needed to be written to / read from Scenes, which was also suboptimal and error prone.
- Repeating render logic was troublesome: Viewports, rendering to multiple textures / windows, and shadow maps were possible, but they required hard-coding, special casing, and boilerplate. This wasn't aligned with our goals for modularity and clarity.
Why now? #
The shortcomings above were acceptable in Bevy's early days, but were clearly holding us back as Bevy grew from a one person side project to the most popular Rust game engine on GitHub (and one of the most popular open source game engines ... period). A "passable" renderer no longer cuts it when we have hundreds of contributors, a paid full-time developer, thousands of individual users, and a growing number of companies paying people to work on Bevy apps and features. It was time for a change.
For a deeper view into our decision-making and development process (including the alternatives we considered) check out the New Renderer Tracking Issue.
Pipelined Rendering: Extract, Prepare, Queue, Render #
Pipelined Rendering is a cornerstone of the new renderer. It accomplishes a number of goals:
- Increased Parallelism: We can now start running the main app logic for the next frame, while rendering the current frame. Given that rendering is often a bottleneck, this can be a huge win when there is also a lot of app work to do.
- Clearer Dataflow and Structure: Pipelining requires drawing hard lines between "app logic" and "render logic", with a fixed synchronization point (which we call the "extract" step). This makes it easier to reason about dataflow and ownership. Code can be organized along these lines, which improves clarity.
From a high level, traditional "non-pipelined rendering" looks like this:

Pipelined rendering looks like this:

Much better!
Bevy apps are now split into the Main App, which is where app logic occurs, and the Render App, which has its own separate ECS World and Schedule. The Render App consists of the following ECS stages, which developers add ECS Systems to when they are composing new render features:
- Extract: This is the one synchronization point between the Main World and the Render World. Relevant Entities, Components, and Resources are read from the Main World and written to corresponding Entities, Components, and Resources in the Render World. The goal is to keep this step as quick as possible, as it is the one piece of logic that cannot run in parallel. It is a good rule of thumb to extract only the minimum amount of data needed for rendering, such as by only considering "visible" entities and only copying the relevant components.
- Prepare: Extracted data is then "prepared" by writing it to the GPU. This generally involves writing to GPU Buffers and Textures and creating Bind Groups.
- Queue: This "queues" render jobs that feed off of "prepared" data.
- Render: This runs the Render Graph, which produces actual render commands from the results stored in the Render World from the Extract, Prepare, and Queue steps.
So pipelined rendering actually looks more like this, with the next app update occurring after the extract step:

As a quick callout, pipelined rendering doesn't actually happen in parallel yet. I have a branch with parallel pipelining enabled, but running app logic in a separate thread currently breaks "non send" resources (because the main app is moved to a separate thread, breaking non send guarantees). There will be a fix for this soon, I just wanted to get the new renderer in peoples' hands as soon as possible! When we enable parallel pipelining, no user-facing code changes will be required.
Render Graphs and Sub Graphs #

The New Bevy Renderer has a Render Graph, much like the old Bevy renderer. Render Graphs are a way to logically model GPU command construction in a modular way. Graph Nodes pass GPU resources like Textures and Buffers (and sometimes Entities) to each other, forming a directed acyclic graph. When a Graph Node runs, it uses its graph inputs and the Render World to construct GPU command lists.
The biggest change to this API is that we now support Sub Graphs, which are basically "namespaced" Render Graphs that can be run from any Node in the graph with arbitrary inputs. This enables us to define things like a "2d" and "3d" sub graph, which users can insert custom logic into. This opens two doors simultaneously:
- The ability to repeat render logic, but for different views (split screen, mirrors, rendering to a texture, shadow maps).
- The ability for users to extend this repeated logic.
Embracing wgpu #
Bevy has always used wgpu, a native GPU abstraction layer with support for most graphics backends: Vulkan, Metal, DX12, OpenGL, WebGL2, and WebGPU (and WIP DX11 support). But the old renderer hid it behind our own hardware abstraction layer. In practice, this was largely just a mirror of the wgpu API. It gave us the ability to build our own graphics backends without bothering the wgpu folks, but in practice it created a lot of pain (due to being an imperfect mirror), overhead (due to introducing a dynamic API and requiring global mutex locks over GPU resource collections), and complexity (bevy_render -> wgpu -> Vulkan). In return, we didn't get many practical benefits ... just slightly more autonomy.
The truth of the matter is that wgpu already occupies exactly the space we want it to:
- Multiple backends, with the goal to support as many platforms as possible
- A "baseline" feature set that works almost everywhere with a consistent API
- A "limits" and "features" system that enables opting-in to arbitrary (sometimes backend-specific features) and detecting when those features are available. This will be important when we start adding things like raytracing and VR support.
- A modern GPU API, but without the pain and complexity of raw Vulkan. Perfect for user-facing Bevy renderer extensions.
However, initially there were a couple of reasons not to make it our "public facing API":
- Complexity: wgpu used to be built on top of gfx-hal (an older GPU abstraction layer also built and managed by the wgpu team). These multiple layers of abstraction in multiple repos made contributing to and reasoning about the internals difficult. Additionally, I have a rule for "3rd party dependencies publicly exposed in Bevy APIs": we must feel comfortable forking and maintaining them if we need to (ex: upstream stops being maintained, visions diverge, etc). I wasn't particularly comfortable with doing that with the old architecture.
- Licensing: wgpu used to be licensed under the "copyleft" MPL license, which created concerns about integration with proprietary graphics APIs (such as consoles like the Switch).
- WebGL2 Support: wgpu used to not have a WebGL2 backend. Bevy's old renderer had a custom WebGL2 backend and we weren't willing to give up support for the Web as a platform.
Almost immediately after we voiced these concerns, @kvark kicked off a relicensing effort that switched wgpu to the Rust-standard dual MIT/Apache-2.0 license. They also removed gfx-hal in favor of a much simpler and flatter architecture. Soon after, @zicklag added a WebGL2 backend. Having resolved all of my remaining hangups, it was clear to me that @kvark's priorities were aligned with mine and that I could trust them to adjust to community feedback.
The New Bevy Renderer tosses out our old intermediate GPU abstraction layer in favor of using wgpu directly as our "low-level" GPU API. The result is a simpler (and faster) architecture with full and direct access to wgpu. Feedback from Bevy Renderer feature developers so far has been very positive.
Bevy was also updated to use the latest and greatest wgpu version: 0.12.
ECS-Driven Rendering #
The new renderer is what I like to call "ECS-driven":
- As we covered previously, the Render World is populated using data Extracted from the Main World.
- Scenes are rendered from one or more Views, which are just Entities in the Render World with Components relevant to that View. View Entities can be extended with arbitrary Components, which makes it easy to extend the renderer with custom View data and logic. Cameras aren't the only type of View. Views can be defined by the Render App for arbitrary concepts, such as "shadow map perspectives".
- Views can have zero or more generic
RenderPhase<T: PhaseItem>Components, where T defines the "type and scope" of thing being rendered in the phase (ex: "transparent 3d entities in the main pass"). At its core, aRenderPhaseis a (potentially sorted) list of Entities to be drawn. - Entities in a RenderPhase are drawn using DrawFunctions, which read ECS data from the Render World and produce GPU commands.
- DrawFunctions can (optionally) be composed of modular DrawCommands. These are generally scoped to specific actions like
SetStandardMaterialBindGroup,DrawMesh,SetItemPipeline, etc. Bevy provides a number of built-in DrawCommands and users can also define their own. - Render Graph Nodes convert a specific View's RenderPhases into GPU commands by iterating each RenderPhases' Entities and running the appropriate Draw Functions.
If that seems complicated ... don't worry! These are what I like to call "mid-level" renderer APIs. They provide the necessary tools for experienced render feature developers to build modular render plugins with relative ease. We also provide easy to use high-level APIs like Materials, which cover the majority of "custom shader logic" use cases.
Bevy's Core Pipeline #
The new renderer is very flexible and unopinionated by default. However, too much flexibility isn't always desirable. We want a rich Bevy renderer plugin ecosystem where developers have enough freedom to implement what they want, while still maximizing compatibility across plugins.
The new bevy_core_pipeline crate is our answer to this problem. It defines a "core" set of Views / Cameras (2d and 3d), Sub Graphs (ClearPass, MainPass2d, MainPass3d), and Render Phases (Transparent2d, Opaque3d, AlphaMask3d, Transparent3d). This provides a "common ground" for render feature developers to build on while still maintaining compatibility with each other. As long as developers operate within these constraints, they should be compatible with the wider ecosystem. Developers are also free to operate outside these constraints, but that also increases the likelihood that they will be incompatible.
Bevy's built-in render features build on top of the Core Pipeline (ex: bevy_sprite and bevy_pbr). The Core Pipeline will continue to expand with things like a standardized "post-processing" effect stack.
Materials #
The new renderer structure gives developers fine-grained control over how entities are drawn. Developers can manually define Extract, Prepare, and Queue systems to draw entities using arbitrary render commands in custom or built-in RenderPhases. However this level of control necessitates understanding the render pipeline internals and involve more boilerplate than most users are willing to tolerate. Sometimes all you want to do is slot your custom material shader into the existing pipelines!
The new Material trait enables users to ignore nitty gritty details in favor of a simpler interface: just implement the Material trait and add a MaterialPlugin for your type. The new shader_material.rs example illustrates this.
// register the plugin for a CustomMaterial
app.add_plugin
There is also a SpecializedMaterial variant, which enables "specializing" shaders and pipelines using custom per-entity keys. This extra flexibility isn't always needed, but when you need it, you will be glad to have it! For example, the built-in StandardMaterial uses specialization to toggle whether or not the Entity should receive lighting in the shader.
We also have big plans to make Material even better:
- Bind Group derives: this should cut down on the boilerplate of passing materials to the GPU.
- Material Instancing: materials enable us to implement high-level mesh instancing as a simple configuration item for both built in and custom materials.
Visibility and Frustum Culling #

Drawing things is expensive! It requires writing data from the CPU to the GPU, constructing draw calls, and running shaders. We can save a lot of time by not drawing things that the camera can't see. "Frustum culling" is the act of excluding objects that are outside the bounds of the camera's "view frustum", to avoid wasting work drawing them. For large scenes, this can be the difference between a crisp 60 frames per second and chugging to a grinding halt.
Bevy 0.6 now automatically does frustum culling for 3d objects using their axis-aligned bounding boxes. We might also enable this for 2d objects in future releases, but the wins there will be less pronounced, as drawing sprites is now much cheaper thanks to the new batched rendering.
Directional Shadows #
Directional Lights can now cast "directional shadows", which are "sun-like" shadows cast from a light source infinitely far away. These can be enabled by setting DirectionalLight::shadows_enabled to true.
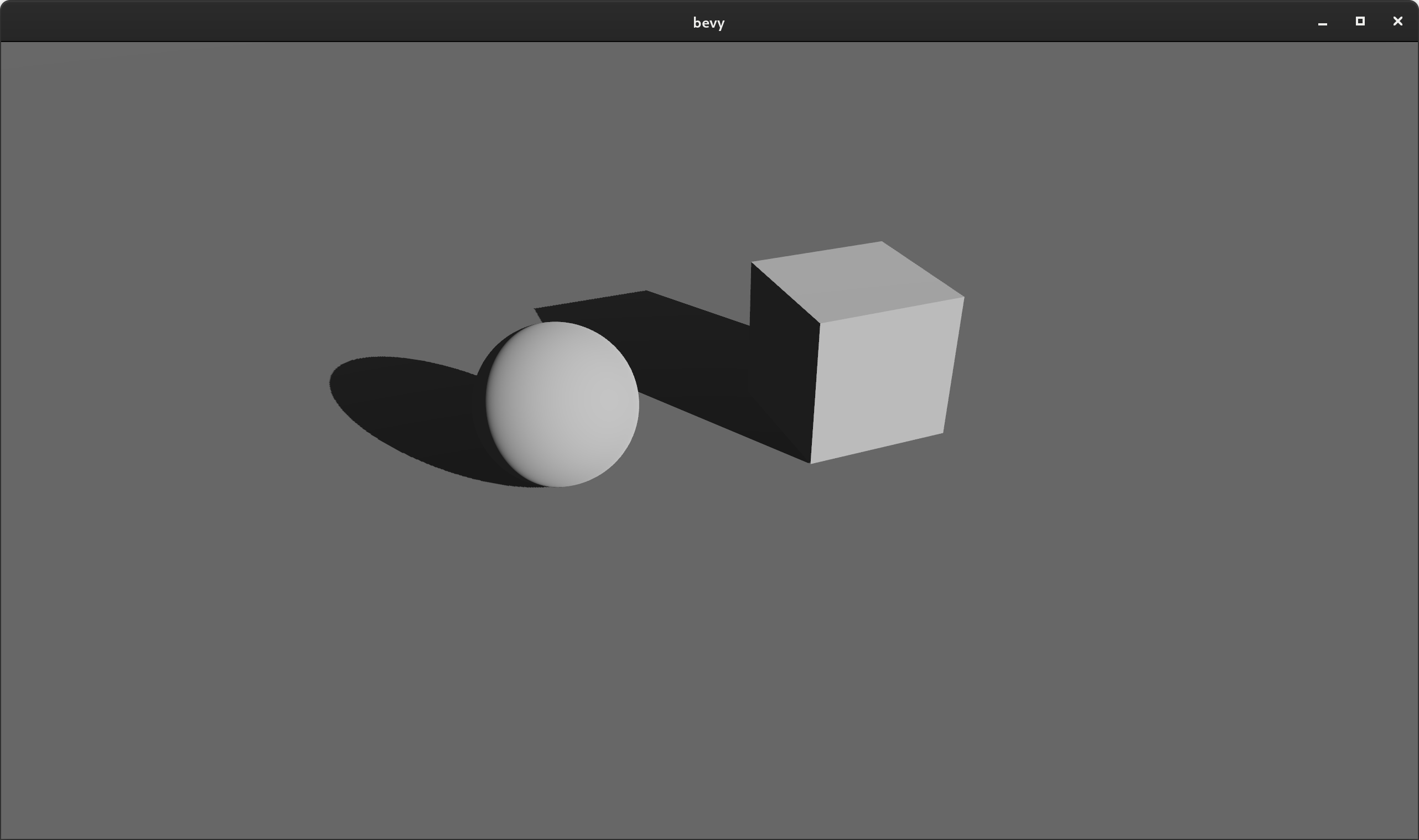
Note: directional shadows currently require more manual configuration than necessary (check out the shadow_projection field in the DirectionalLight setup in the shadow_biases.rs example). We will soon make this automatic and better quality over a larger range through cascaded shadow maps.
Point Light Shadows #
Point lights can now cast "omnidirectional shadows", which can be enabled by setting PointLight::shadows_enabled to true:
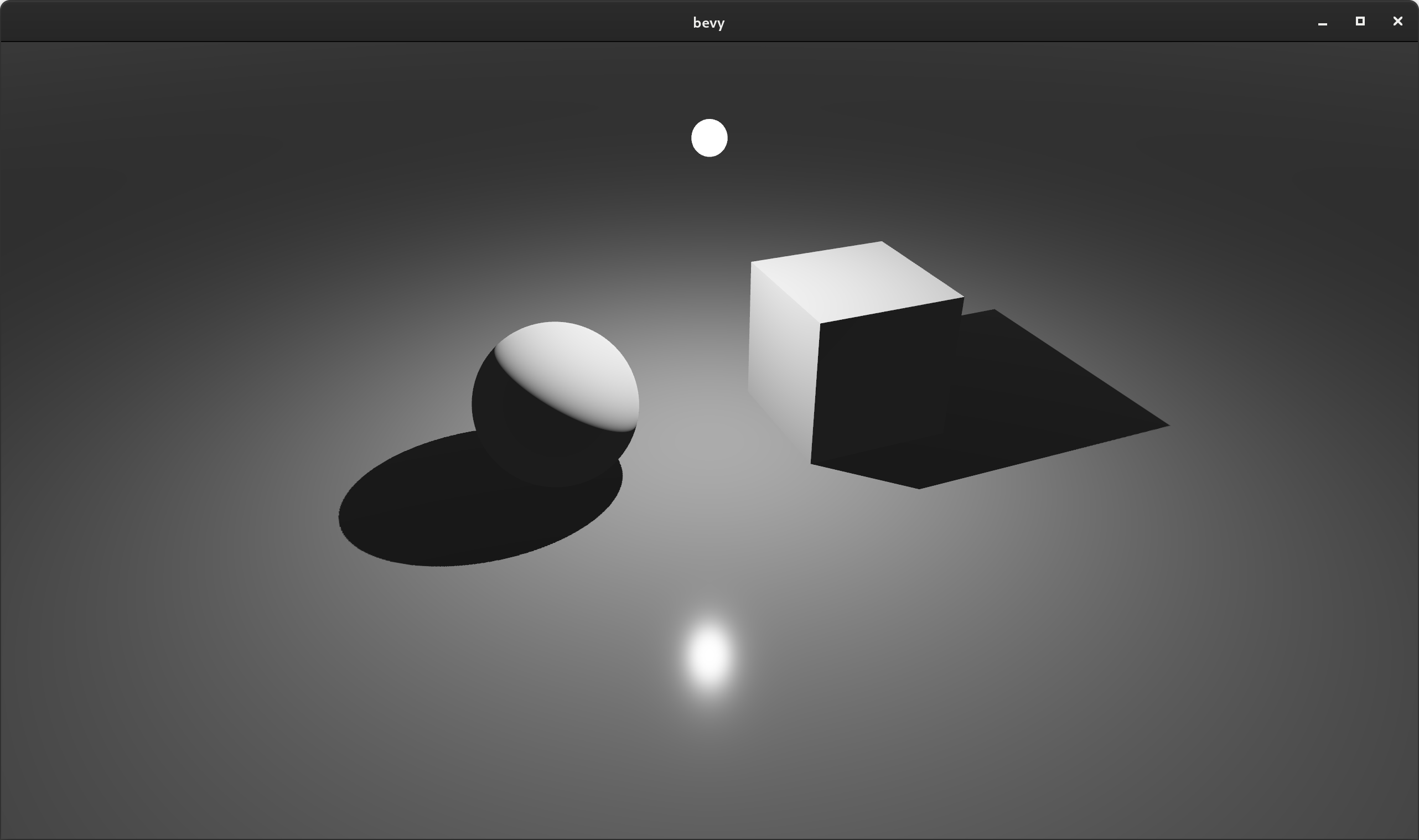
Enabling and Disabling Entity Shadows #
Mesh entities can opt out of casting shadows by adding the NotShadowCaster component.
commands.entity.insert;
Likewise, they can opt out of receiving shadows by adding the NotShadowReceiver component.
commands.entity.insert;
Spherical Area Lights #
PointLight Components can now define a radius value, which controls the size of the sphere that emits light. A normal zero-sized "point light" has a radius of zero.
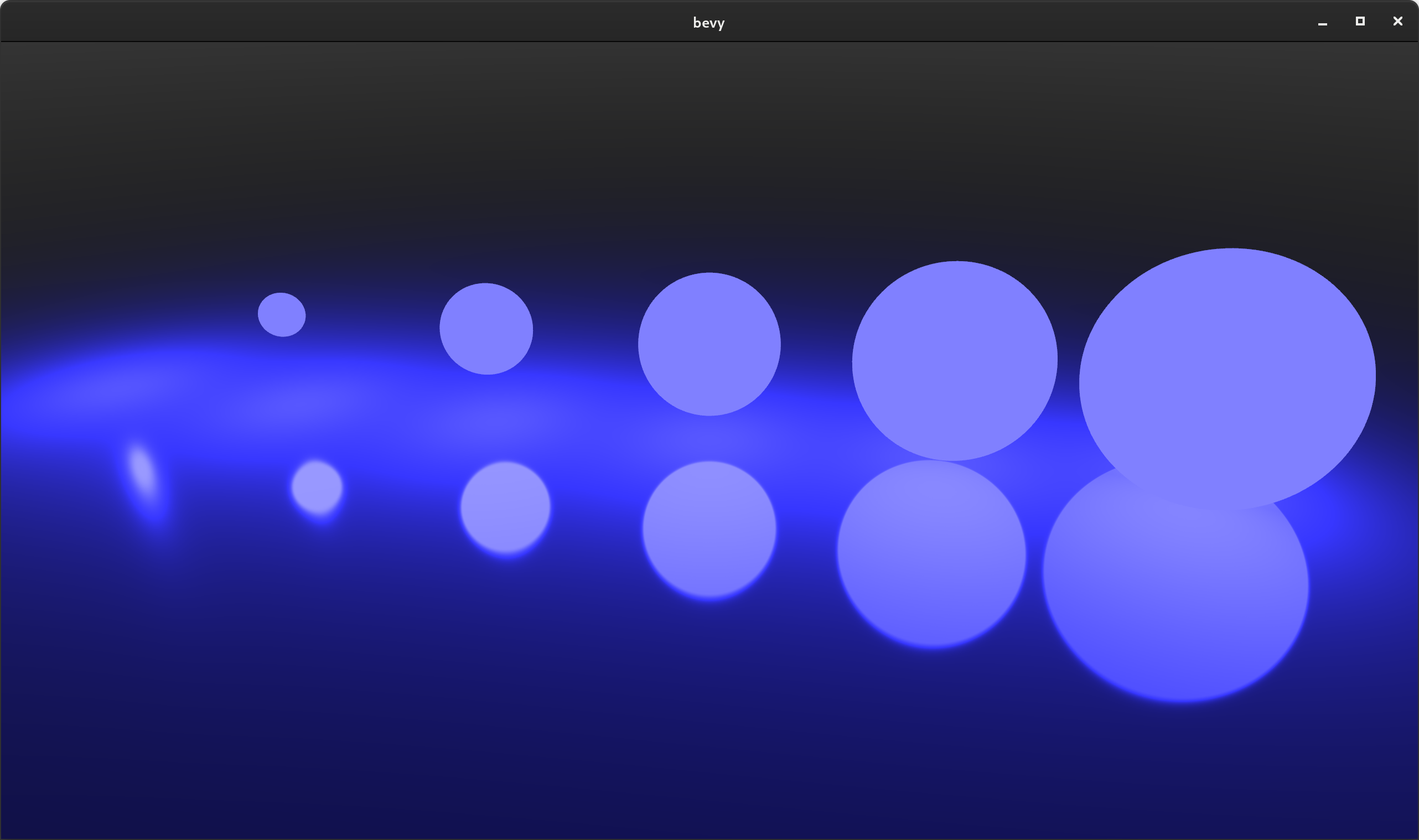
(Note that lights with a radius don't normally take up physical space in the world ... I added meshes to help illustrate light position and size)
Configurable Alpha Blend Modes #
Bevy's StandardMaterial now has an alpha_mode field, which can be set to AlphaMode::Opaque, AlphaMode::Mask(f32), or AlphaMode::Blend. This field is properly set when loading GLTF scenes.
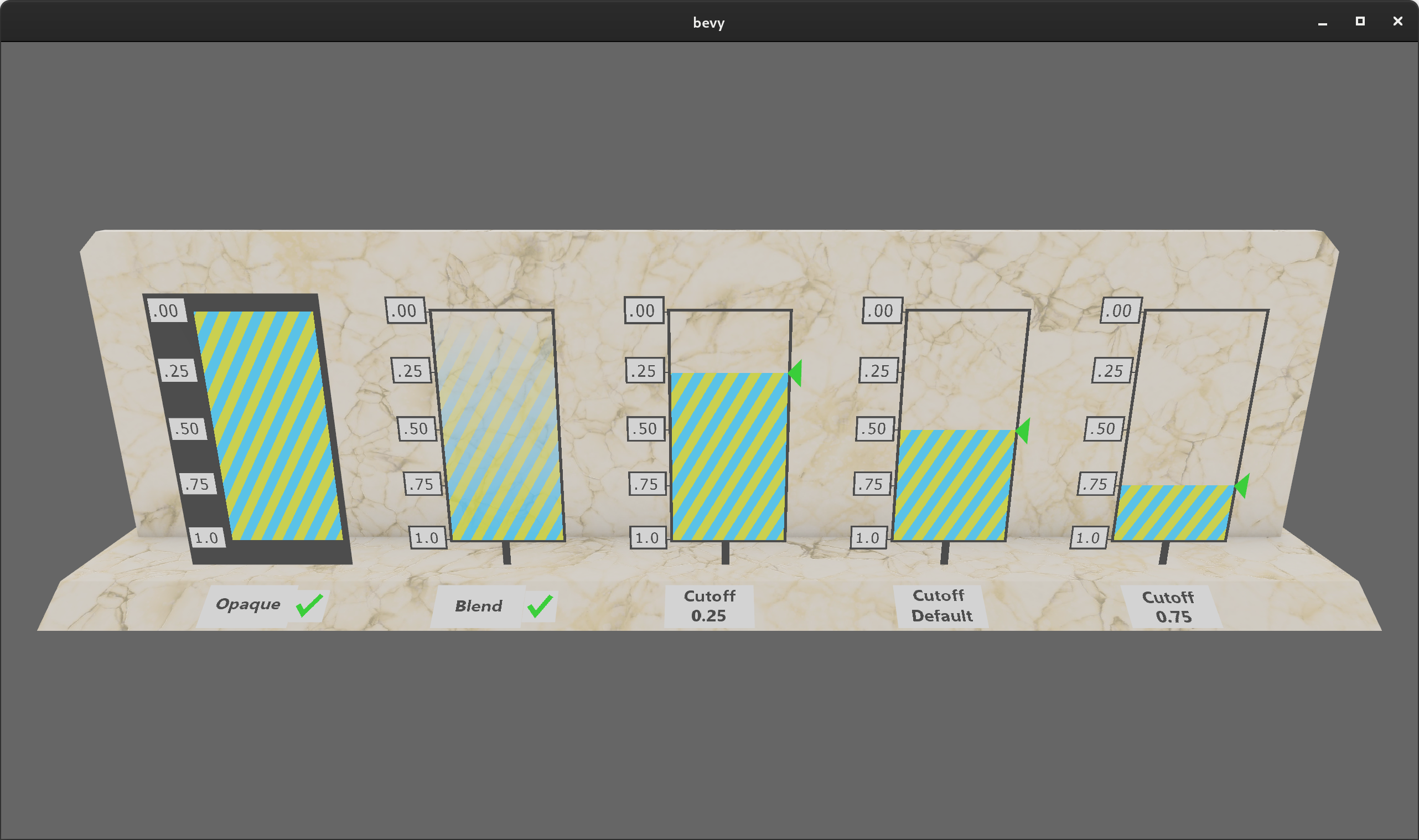
Clustered Forward Rendering #
Modern scenes often have many point lights. But when rendering scenes, calculating lighting for each light, for each rendered fragment rapidly becomes prohibitively expensive as the number of lights in the scene increases. Clustered Forward Rendering is a popular approach that increases the number of lights you can have in a scene by dividing up the view frustum into "clusters" (a 3d grid of sub-volumes). Each cluster is assigned lights based on whether they can affect that cluster. This is a form of "culling" that enables fragments to ignore lights that aren't assigned to their cluster.
In practice this can significantly increase the number of lights in the scene:
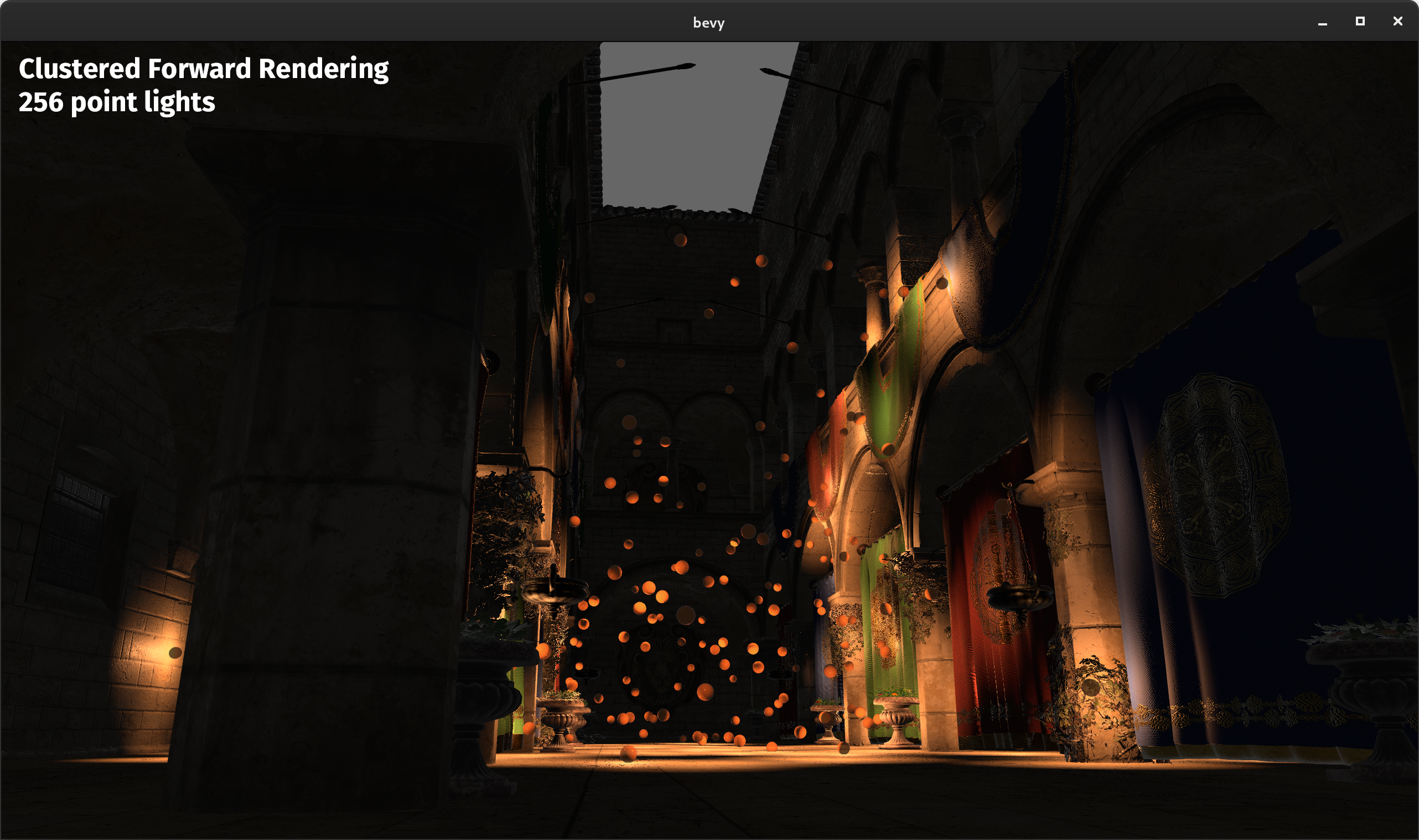
Clusters are 3d subdivisions of the view frustum. They are cuboids in projected space so for a perspective projection, they are stretched and skewed in view space. When debugging them in screen space, you are looking along a row of clusters and so they look like squares. Different colors within a square represent mesh surfaces being at different depths in the scene and so they belong to different clusters:

The current implementation is limited to at most 256 lights as we initially prioritized cross-platform compatibility so that everyone could benefit. WebGL2 specifically does not support storage buffers and so the implementation is currently constrained by the maximum uniform buffer size. We can support many more lights on other platforms by using storage buffers, which we will add support for in a future release.
Click here for a video that illustrates Bevy's clustered forward rendering.
Sprite Batching #
Sprites are now rendered in batches according to their texture within a z-level. They are also opportunistically batched across z-levels. This yields significant performance wins because it drastically reduces the number of draw calls required. Combine that with the other performance improvements in the new Bevy Renderer and things start to get very interesting! On my machine, the old Bevy renderer generally started dropping below 60fps at around 8,000 sprites in our "bevymark" benchmark. With the new renderer on that same machine I can get about 100,000 sprites!
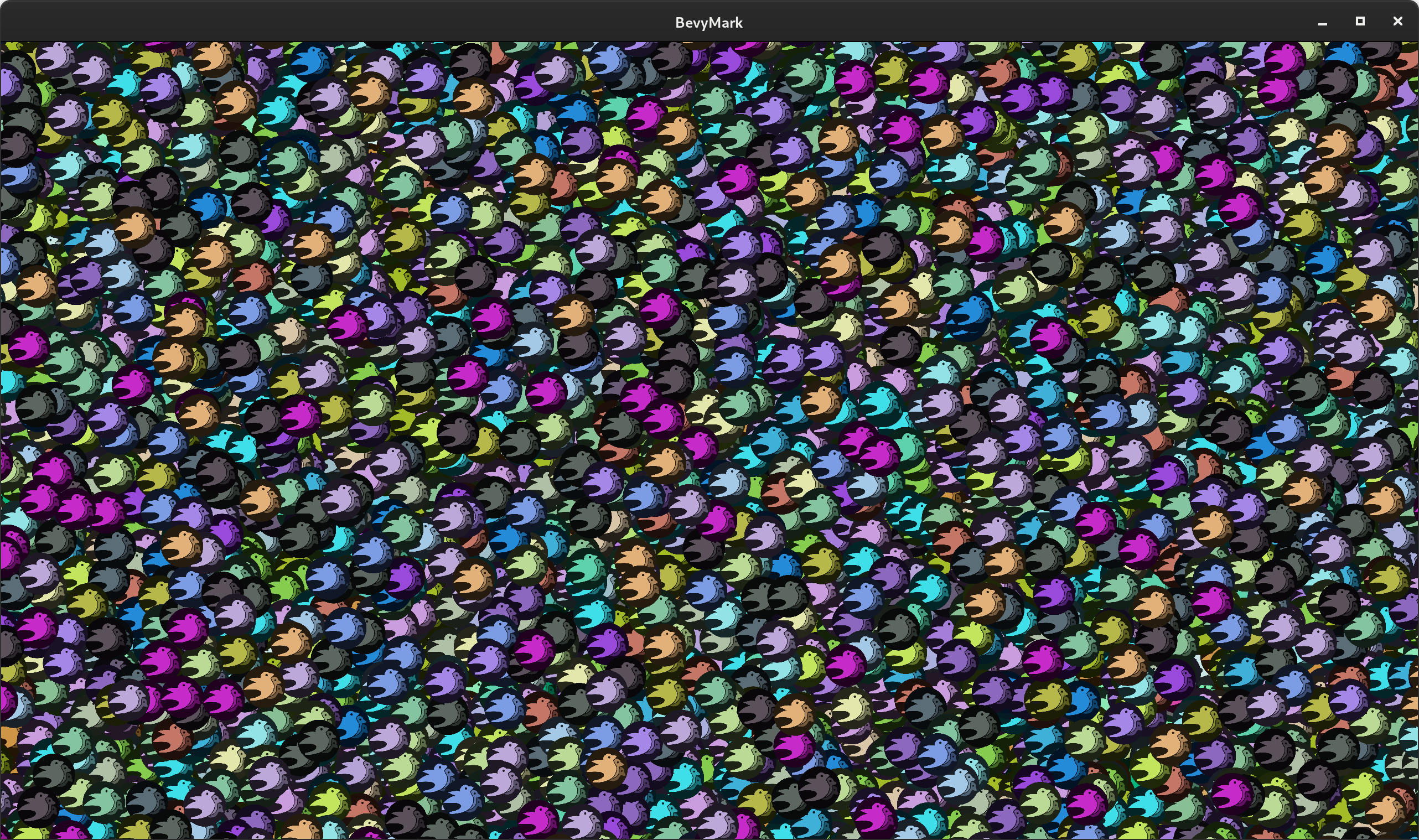
My machine: Nvidia GTX 1070, Intel i7 7700k, 16GB ram, Arch Linux
Sprite Ergonomics #
Sprite entities are now simpler to spawn:
No need to manage sprite materials! Their texture handle is now a direct component and color can now be set directly on the Sprite component.To compare, expand this to see the old Bevy 0.5 code
// Old (Bevy 0.5)
WGSL Shaders #
Bevy now uses WGSL for our built-in shaders and examples. WGSL is a new shader language being developed for WebGPU (although it is a "cross platform" shader language just like GLSL). Bevy still supports GLSL shaders, but WGSL is nice enough that, for now, we are treating it as our "officially recommended" shader language. WGSL is still being developed and polished, but given how much investment it is receiving I believe it is worth betting on. Consider this the start of the "official Bevy shader language" conversation, not the end of it.
view: View;
mesh: Mesh;
;
;
Shader Preprocessor #
Bevy now has its own custom shader preprocessor. It currently supports #import, #ifdef FOO, #ifndef FOO, #else, and #endif, but we will be expanding it with more features to enable simple, flexible shader code reuse and extension.
Shader preprocessors are often used to conditionally enable shader code:
#ifdef TEXTURE
var sprite_texture: ;
#endif
This pattern is very useful when defining complicated / configurable shaders (such as Bevy's PBR shader).
Shader Imports #
The new preprocessor supports importing other shader files (which pulls in their entire contents). This comes in two forms:
Asset path imports:
#import "shaders/cool_function.wgsl"
Plugin-provided imports, which can be registered by Bevy Plugins with arbitrary paths:
#import mesh_view_bind_group
We also plan to experiment with using Naga for "partial imports" of specific, named symbols (ex: import a specific function or struct from a file). It's a 'far out' idea, but this could also enable using Naga's intermediate shader representation as a way of combining pieces of shader code written in different languages into one shader.
Pipeline Specialization #
When shaders use a preprocessor and have multiple permutations, the associated "render pipeline" needs to be updated to accommodate those permutations (ex: different Vertex Attributes, Bind Groups, etc). To make this process straightforward, we added the SpecializedPipeline trait, which allows defining specializations for a given key:
Implementors of this trait can then easily and cheaply access specialized pipeline variants (with automatic per-key caching and hot-reloading). If this feels too abstract / advanced, don't worry! This is a "mid-level power-user tool", not something most Bevy App developers need to contend with.
Simpler Shader Stack #
Bevy now uses Naga for all of its shader needs. As a result, we were able to remove all of our complicated non-rust shader dependencies: glsl_to_spirv, shaderc, and spirv_reflect. glsl_to_spirv was a major producer of platform-specific build dependencies and bugs, so this is a huge win!
Features Ported to the New Renderer #
Render logic for internal Bevy crates had to be rewritten in a number of cases to take advantage of the new renderer. The following people helped with this effort:
- bevy_sprites: @cart, @StarArawn, @Davier
- bevy_pbr: Rob Swain (@superdump), @aevyrie, @cart, @zicklag, @jakobhellermann
- bevy_ui: @Davier
- bevy_text: @Davier
- bevy_gltf: Rob Swain (@superdump)
WebGL2 Support #
Bevy now has built-in support for deploying to the web using WebGL2 / WASM, thanks to @zicklag adding a native WebGL2 backend to wgpu. There is now no need for the third party bevy_webgl2 plugin. Any Bevy app can be deployed to the web by running the following commands:
cargo build --target wasm32-unknown-unknown
wasm-bindgen --out-dir OUTPUT_DIR --target web TARGET_DIR
The New Bevy Renderer developers prioritized cross-platform compatibility for the initial renderer feature implementation and so had to carefully operate within the limits of WebGL2 (ex: storage buffers and compute shaders aren't supported in WebGL2), but the results were worth it! Over time, features will be implemented that leverage more modern/advanced features such as compute shaders. But it is important to us that everyone has access to a solid visual experience for their games and applications regardless of their target platform(s).
You can try out Bevy's WASM support in your browser using our new Bevy Examples page:
Infinite Reverse Z Perspective Projection #
For improved precision in the "useful range", the industry has largely adopted "reverse projections" with an "infinite" far plane. The new Bevy renderer was adapted to use the "right-handed infinite reverse z" projection. This Nvidia article does a great job of explaining why this is so worthwhile.
Compute Shaders #
The new renderer makes it possible for users to write compute shaders. Our new "compute shader game of life" example (by @jakobhellermann) illustrates how to write compute shaders in Bevy.

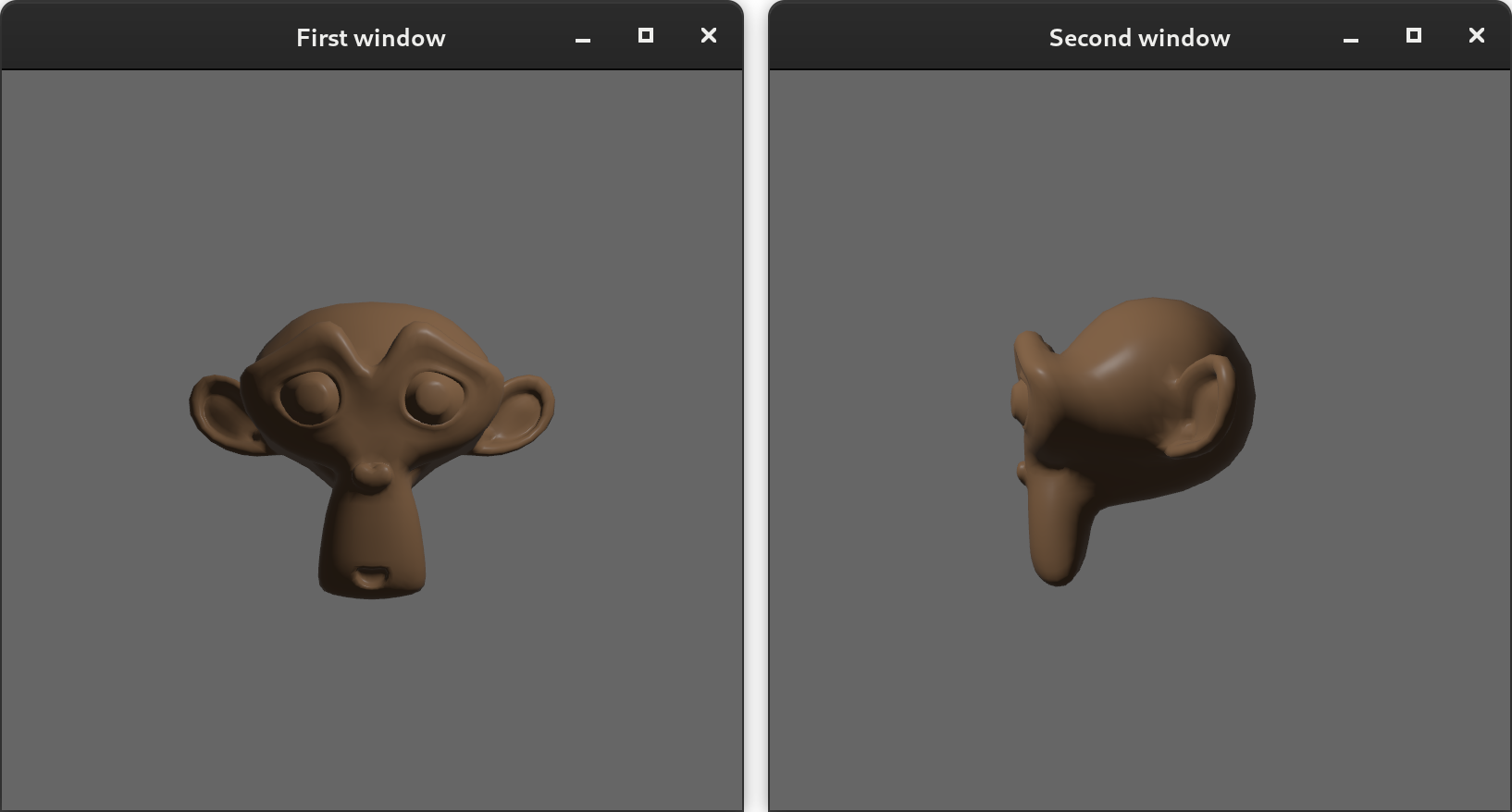
New Multiple Windows Example #
The "multiple windows" example has been updated to use the new renderer APIs. Thanks to the new renderer APIs, this example is now much nicer to look at (and will look even nicer when we add high-level Render Targets).
Crevice #
Bevy's old Bytes abstraction has been replaced with a fork of the crevice crate (by @LPGhatguy), which makes it possible to write normal Rust types to GPU-friendly data layouts. Namely std140 (uniform buffers default to this layout) and std430 (storage buffers default to this layout). Bevy exports AsStd140 and AsStd430 derives:
Coupling an AsStd140 derive with our new UniformVec<T> type makes it easy to write Rust types to shader-ready uniform buffers:
// WGSL shader
;
mesh: Mesh;
We (in the short term) forked crevice for a couple of reasons:
- To merge Array Support PR by @ElectronicRU, as we need support for arrays in our uniforms.
- To re-export crevice derives and provide an "out of the box" experience for Bevy
Ultimately, we'd like to move back upstream if possible. A big thanks to the crevice developers for building such useful software!
UV Sphere Mesh Shape #
Bevy now has a built-in "uv sphere" mesh primitive.
from
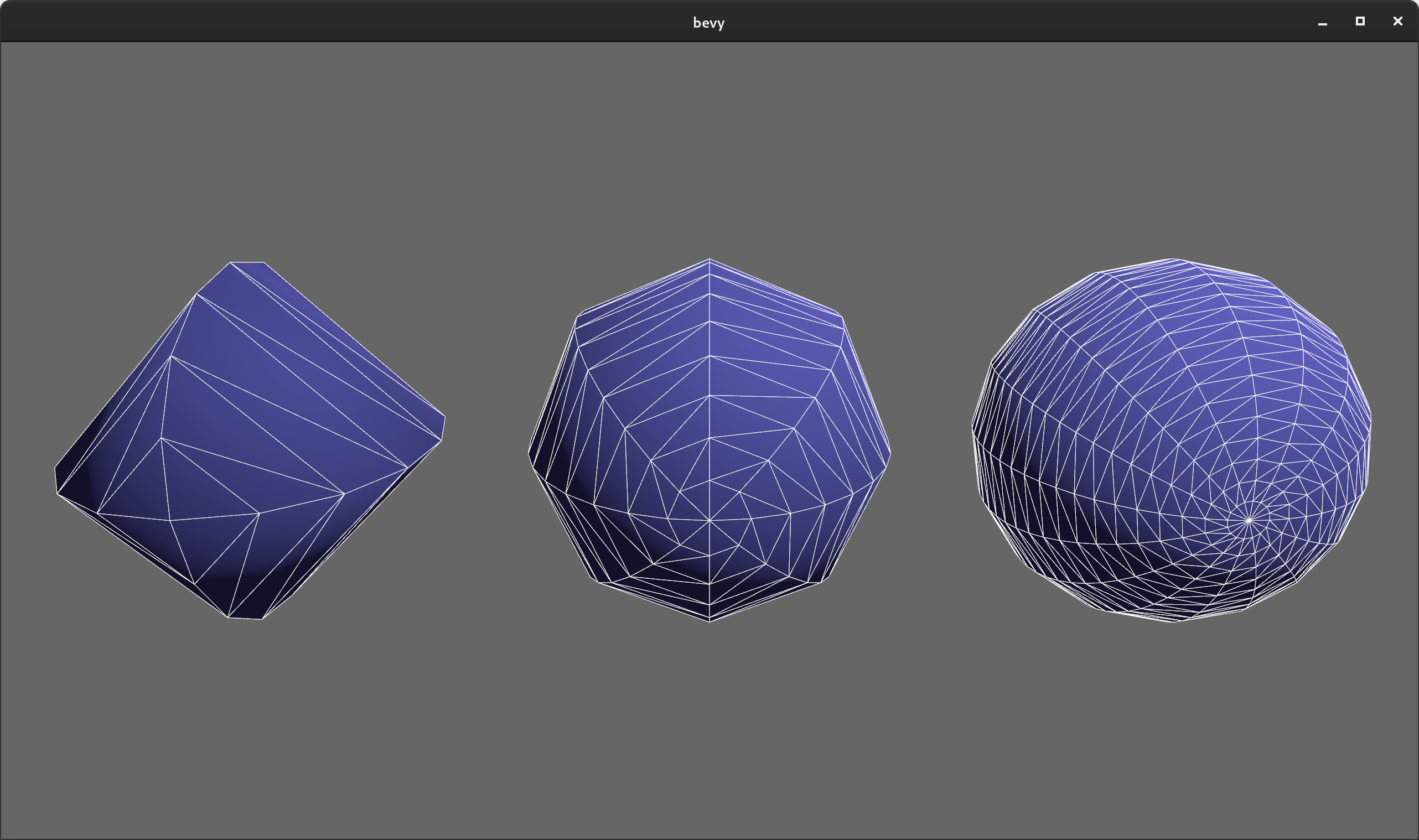
Flat Normal Computation #
The Mesh type now has a compute_flat_normals() function. Imported GLTF meshes without normals now automatically have flat normals computed, in accordance with the GLTF spec.
Faster GLTF Loading #
@DJMcNab fixed nasty non-linear loading of GLTF nodes, which made them load much faster. One complicated scene went from 40 seconds to 0.2 seconds. Awesome!
@mockersf made GLTF textures load asynchronously in Bevy's "IO task pool", which almost halved GLTF scene load times in some cases.
We are also in the process of adding "compressed texture loading", which will substantially speed up GLTF scene loading, especially for large scenes!
Bevy ECS #
No more .system()! #
One of our highest priorities for Bevy ECS is "ergonomics". In the past I have made wild claims that Bevy ECS is the most ergonomic ECS in existence. We've spent gratuitous amounts of R&D pioneering new API techniques and I believe the results speak for themselves:
// This is a standalone Bevy 0.5 App that adds a simple `gravity` system to the App's schedule
// and automatically runs it in parallel with other systems
I believe we were already the best in the market by a wide margin (especially if you take into account our automatic parallelization and change detection), but we had one thing holding us back from perfection ... that pesky .system()! We've tried removing it a number of times, but due to rustc limitations and safety issues, it always eluded us. Finally, @DJMcNab found a solution. As a result, in Bevy 0.6 you can now register the system above like this:
// pure bliss!
new
.add_plugins
.add_system
.run;
The New Component Trait and #[derive(Component)] #
In Bevy 0.6 types no longer implement the Component trait by default. Before you get angry ... stick with me for a second. I promise this is for the best! In past Bevy versions, we got away with "auto implementing" Component for types using this "blanket impl":
This removed the need for users to manually implement Component for their types. Early on this seemed like an ergonomics win with no downsides. But Bevy ECS, our understanding of the problem space, and our plans for the future have changed a lot since then:
- It turns out not everything should be a Component: Our users constantly accidentally add non-component types as components. New users accidentally adding Bundles and type constructors as Components are our most common
#helpchannel threads on our Discord. This class of error is very hard to debug because things just silently "don't work". When not everything is a Component, rustc can properly yell at you with informative errors when you mess up. - Optimizations: If we implement Component for everything automatically, we can't customize the
Componenttrait with associated types. This prevents an entire class of optimization. For example, Bevy ECS now has multiple Component storage types. By moving the storage type intoComponent, we enable rustc to optimize checks that would normally need to happen at runtime. @Frizi was able to significantly improve our Query iterator performance by moving the storage type intoComponent. I expect us to find more optimizations in this category. - Automatic registration: Moving more logic into
Componentalso gives us the ability to do fancier things in the future like "automatically registering Reflect impls when derivingComponent". Non-blanketComponentimpls do add a small amount of boilerplate, but they also have the potential to massively reduce the "total boilerplate" of an app. - Documentation: Deriving
Componentserves as a form of self-documentation. It's now easy to tell what types are components at a glance. - Organized: In Bevy 0.5
Component-specific configuration like "storage type" had to be registered in a centralized Plugin somewhere. Moving Component configuration into theComponenttrait allows users to keep "Component type information" right next to the type itself. - Event Handlers: Non-blanket
Componentimpls will eventually allow us to add event handlers likeon_insert(world: &mut World)to theComponenttrait. Very useful!
Hopefully by now you're convinced that this is the right move. If not ... I'm sorry ... you still need to implement Component manually in Bevy 0.6. You can either derive Component:
// defaults to "Table" storage
;
// overrides the default storage
;
Or you can manually implement it:
;
iter() for mutable Queries #
Mutable queries can now be immutably iterated, returning immutable references to components:
Compare that to the complicated QuerySet that this would have needed in previous Bevy versions to avoid conflicting immutable and mutable Queries:
// Gross!
SystemState #
Have you ever wanted to use "system params" directly with a Bevy World? With SystemState, now you can!
let mut system_state: = new;
let = system_state.get;
For those working directly with World, this is a game changer. It makes it possible to mutably access multiple disjoint Components and Resources (often eliminating the need for more costly abstractions like WorldCell).
SystemState does all of the same caching that a normal Bevy system does, so reusing the same SystemState results in uber-fast World access.
Sub Apps #
The new Bevy renderer requires strict separation between the "main app" and the "render app". To enable this, we added the concept of "sub-apps":
;
let mut render_app = empty;
app.add_sub_app;
// later
app.sub_app_mut
.add_system;
.add_system;
We plan on exposing more control over scheduling, running, and working with sub-apps in the future.
Query::iter_combinations #
You can now iterate all combinations of N entities for a given query:
This is especially useful for things like "checking for entities for collisions with all other entities". There is also an iter_combinations_mut variant. Just be careful ... the time complexity of this grows exponentially as the number of entities in your combinations increases. With great power comes great responsibility!
The new iter_combinations example illustrates how to use this new API to calculate gravity between objects in a "solar system":
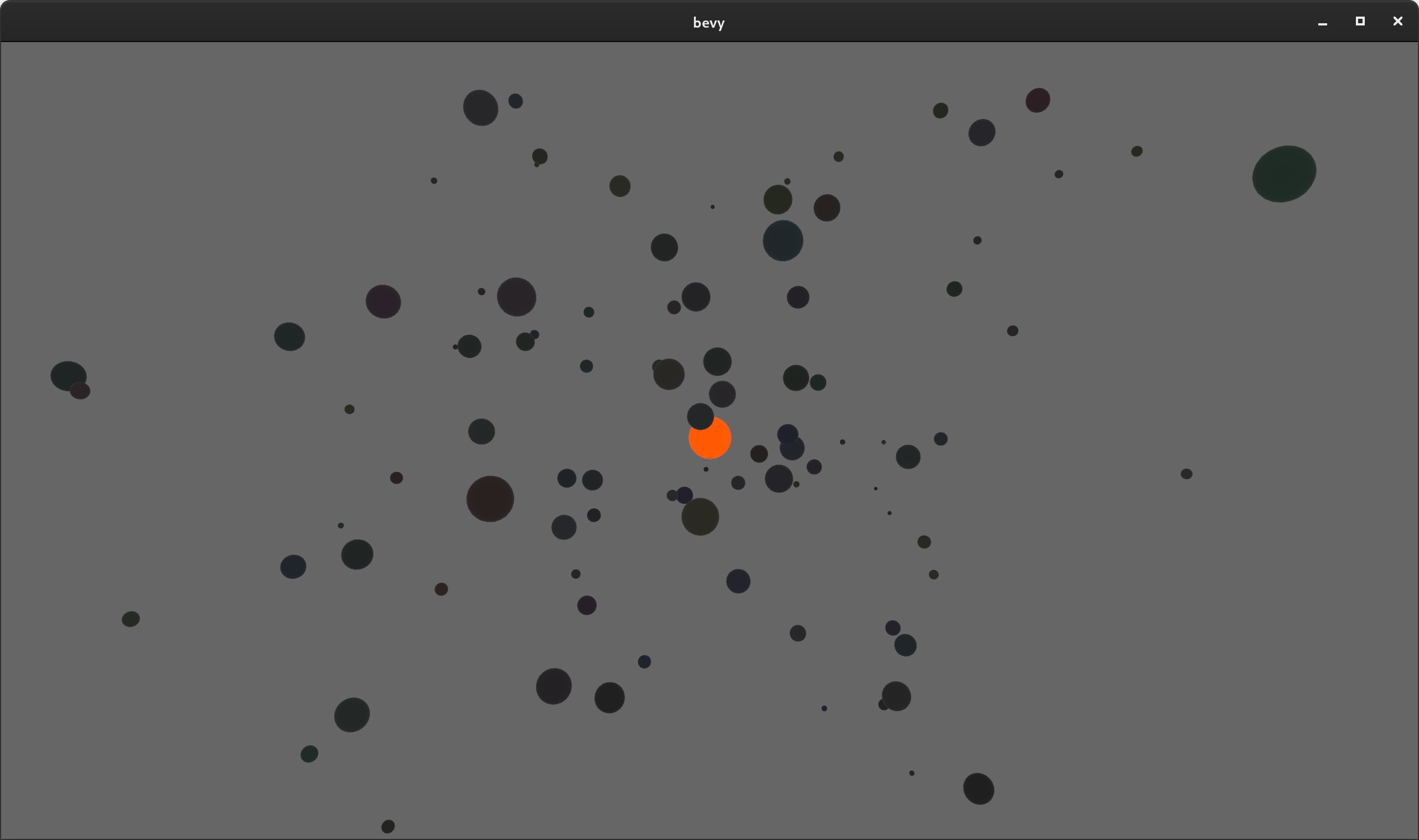
Optimized System Commands #
System Commands got a nice performance boost by changing how command buffers are stored and reused:
Entity Spawn Benchmark Duration (in microseconds, less is better) #
This benchmark spawns entities with a variety of component compositions to ensure we cover a variety of cases. Treat these numbers as relatives, not absolutes.

System Param Lifetimes #
System and Query lifetimes were made more explicit by splitting out the 'system and 'world, lifetimes and using them explicitly where possible. This enables Rust to reason about ECS lifetimes more effectively, especially for read-only lifetimes. This was particularly important because it enabled the new Bevy Renderer to convince wgpu that ECS resources actually live for as long as the Render World.
Note that this does make the lifetimes on SystemParam derives slightly more complicated as a result:
Soundness / Correctness Improvements #
Bevy ECS received a solid number of soundness and correctness bug fixes this release, alongside some unsafe code block removals. Queries and internal storages like Tables and BlobVecs in particular had a number of fixes and improvements in these areas. As Bevy ECS matures, our bar for unsafe code blocks and soundness must also mature. Bevy ECS will probably never be 100% free of unsafe code blocks, because we are modeling parallel data access that Rust literally cannot reason about without our help. But we are committed to removing as much unsafe code as we can (and we have a number of refactors in the works to further improve the situation).
Hierarchy Convenience Functions #
// Despawns all descendants of an entity (its children, its childrens' children, etc)
commands.entity.despawn_descendants;
// Removes the given children from the entity
commands.entity.remove_children;
UI #
Overflow::Hidden #
UI now respects the flexbox Overflow::Hidden property. This can be used to cut off child content, which is useful when building things like scrollable lists:
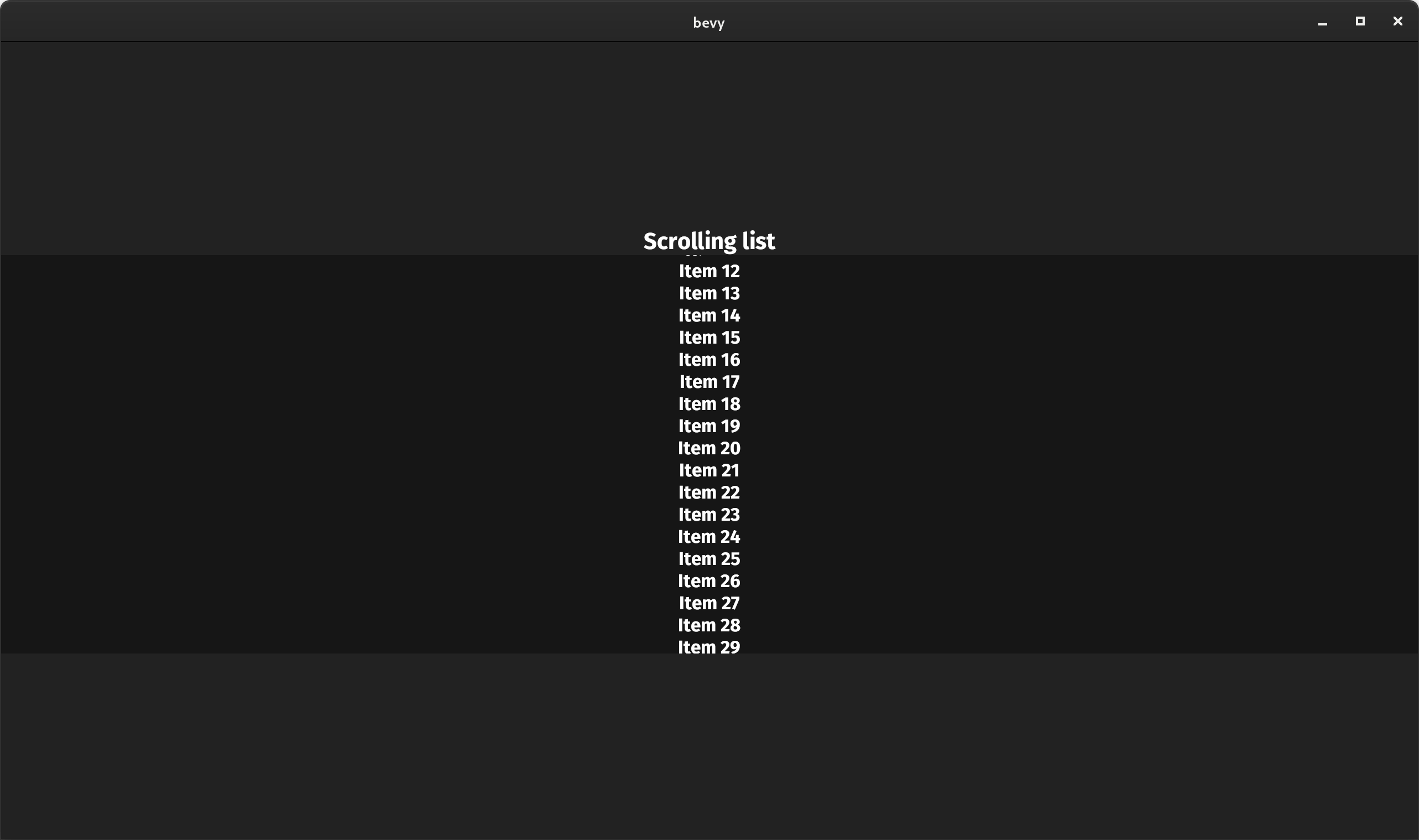
Text2D Transforms #
Text2d now supports arbitrary transformations using the Transform component:

Note that while Transform::scale does have its uses, it is generally still a good idea to adjust text size using the "font size" to ensure it renders "crisply".
Window Transparency #
Winit's "window transparency" feature is now exposed in Bevy's Window type. This allows users to build "widget like" apps without backgrounds or window decorations (on platforms that support it). Here is a Bevy app with a transparent background, rendering a Bevy Logo sprite on top of my Linux desktop background. Seamless! Cool!

Transforms #
Friendly Directional Vectors #
Bevy Transforms now have friendly "directional" functions that return relative vectors:
// Points to the left of the transform
let left: Vec4 = transform.left;
// Points to the right of the transform
let right: Vec4 = transform.right;
// Points up from the transform
let up: Vec4 = transform.up;
// Points down from the transform
let down: Vec4 = transform.down;
// Points forward from the transform
let forward: Vec4 = transform.forward;
// Points back from the transform
let back: Vec4 = transform.back;
Transform Builder Methods #
Transforms now have helpful with_translation(), with_rotation(), and with_scale() builder methods:
from_xyz.with_scale
Rust 2021 #
Bevy has been updated to use Rust 2021. This means we can take advantage of the new Cargo feature resolver by default (which both Bevy and the new wgpu version require). Make sure you update your crates to Rust 2021 or you will need to manually enable the new feature resolver with resolver = "2" in your Cargo.toml.
[]
= "your_app"
= "0.1.0"
= "2021"
Note that "virtual Cargo workspaces" still need to manually define resolver = "2", even in Rust 2021. Refer to the Rust 2021 documentation for details.
[]
= "2" # Important! wgpu/Bevy needs this!
= [ "my_crate1", "my_crate2" ]
Input #
Gamepads Resource #
Bevy 0.6 adds a Gamepads resource, which automatically maintains a collection of connected gamepads.
Input "any" variants #
Input collections now have an any_pressed() function, which returns true when any of the given inputs are pressed.
Profiling #
More Spans #
The new renderer now has tracing spans for frames, the render app schedule, and the Render Graph (with named Sub Graphs spans). The system executor now has finer grained spans, filling in most of the remaining blanks. Applying System Commands also now has spans.
(ignore those weird characters in the spans ... we're investigating that)
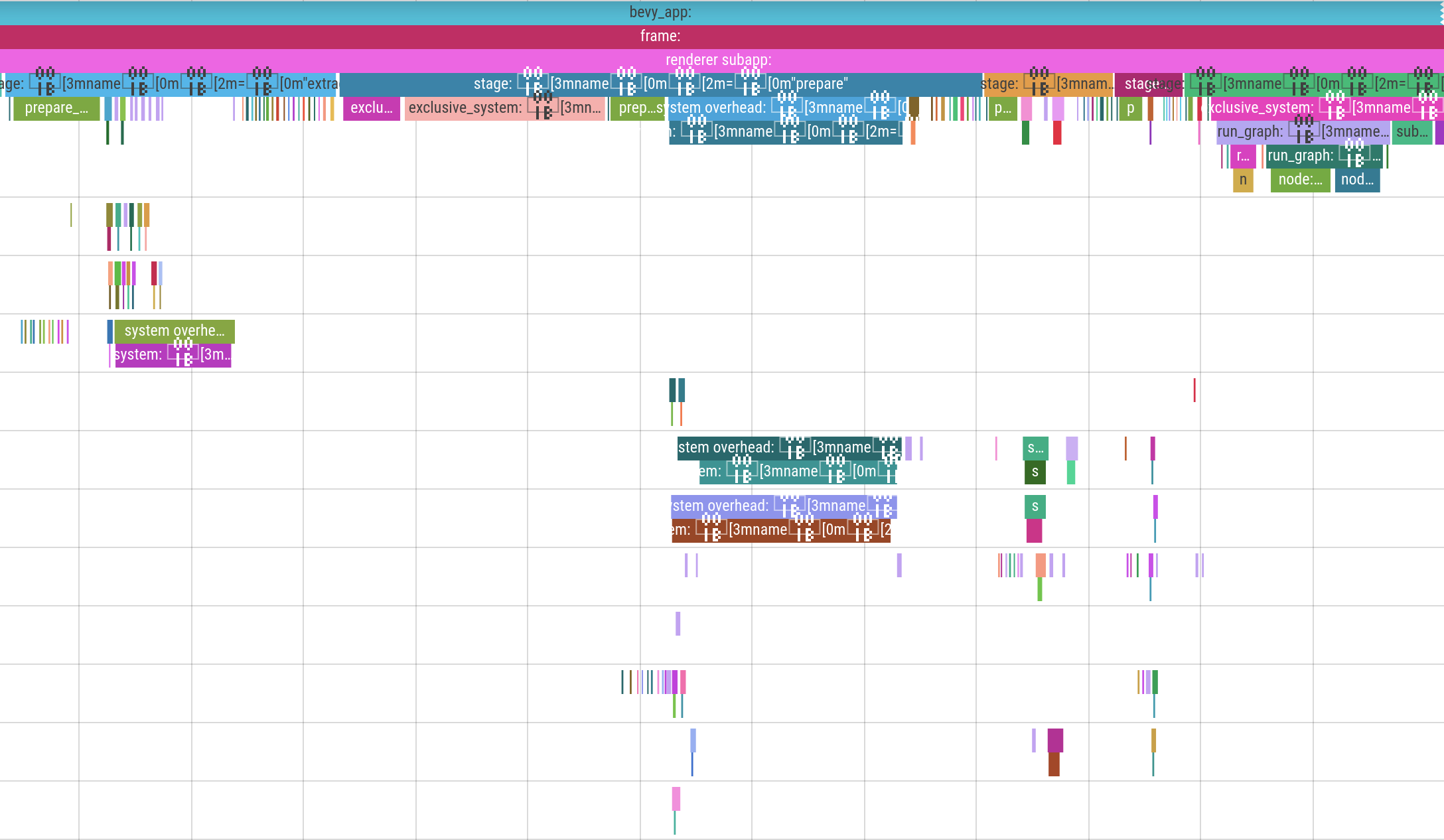
Tracy Backend #
Bevy now supports the tracy profiler via the trace_tracy Cargo feature.
FromReflect Trait and Derive #
Types can now derive the new FromReflect trait, which enables creating "clones" of a type using arbitrary Reflect impls. This is currently used to make reflected collection types (like Vec) work properly, but it will also be useful for "round trip" conversions to and from Reflect types.
let foo = from_reflect.unwrap;
Bevy Error Codes #
To make it easier to search for and discuss common Bevy errors, we decided to add a formal error codes system, much like the one that rustc uses;
Error codes and their descriptions also have an automatically-generated page on the Bevy website.
Bevy Assets #
The curated awesome-bevy GitHub repo containing a list of Bevy plugins, crates, apps, and learning resources is now reborn as Bevy Assets!
Bevy Assets introduces:
- A structured toml format
- Asset icons
- bevy-website integration
This is just the beginning! We have plans to integrate with crates.io and GitHub, improve indexing / tagging / searchability, add asset-specific pages, prettier styles, content delivery, and more. Ultimately we want this to grow into something that can enable first-class, modern asset-driven workflows.
We have automatically migrated existing awesome-bevy entries, but we encourage creators to customize them! If you are working on something Bevy related, you are highly encouraged to add a Bevy Assets entry.
Dual MIT / Apache-2.0 License #
Thanks to the relevant contributors (all 246 of them), Bevy is now dual licensed under MIT and Apache-2.0, at the developers' option. This means developers have the flexibility to choose the license that best suits their specific needs. I want to stress that this is now less restrictive than MIT-only, not more.
I originally chose to license Bevy exclusively under MIT for a variety of reasons:
- People and companies generally know and trust the MIT license more than any other license. Apache 2.0 is less known and trusted.
- It is short and easy to understand
- Many people aren't familiar with the "multiple license options ... choose your favorite" approach. I didn't want to scare people away unnecessarily.
- Other open source engines like Godot have had a lot of success with MIT-only licensing
However, there were a variety of issues that have come up that make dual-licensing Bevy under both MIT and Apache-2.0 compelling:
- The MIT license (arguably) requires binaries to reproduce countless copies of the same license boilerplate for every MIT library in use. Apache-2.0 allows us to compress the boilerplate into a single instance of the license.
- The Apache-2.0 license has protections from patent trolls and an explicit contribution licensing clause.
- The Rust ecosystem is largely Apache-2.0. Being available under that license is good for interoperation and opens the doors to upstreaming Bevy code into other projects (Rust, the async ecosystem, etc).
- The Apache license is incompatible with GPLv2, but MIT is compatible.
Bevy Org Changes #
More pull request mergers! #
I've been at my scalability limits for a while. It has been cough... challenging... to build the engine features I need to, review every single pull request quickly, and preserve my mental health. I've made it this far... sometimes by overworking myself and sometimes by letting PRs sit unmerged for longer than I'd like. By scaling out, we can have our cake and eat it too!
- @mockersf now has merge rights for "uncontroversial changes"
- @alice-i-cecile now has merge rights for "uncontroversial documentation changes"
New issue labels #
After much discussion about naming conventions and colors, we finally have a fresh new set of issue labels (loosely inspired by the rust repo). The Bevy Triage Team can finally express themselves fully!
Comprehensive CONTRIBUTING.md #
We now have a relatively complete Contributors Guide. If you are interested in contributing code or documentation to Bevy, that is a great place to start!
CI Build System Improvements #
We made a ton of CI improvements this release:
- We now fail on cargo doc warnings
- We now use cargo deny to protect against vulnerabilities, duplicate dependencies, and invalid licenses
- PRs are now automatically labeled with the
S-Needs-Triagelabel - Ci stability and speed improvements
- We now check that our benchmarks build
- We now assert compiler errors for compile_fail tests, giving us much stricter guarantees
- Examples are now run using lavapipe (instead of swiftshader) for faster CI validation
What's Next For Bevy? #
Bevy development continues to pick up steam, and we have no intention to slow down now! In addition to the many RFCs we have in the works, we also plan on tackling the following over the next few months:
The "Train" Release Schedule #
In the last two Bevy releases we made massive, sweeping changes to core systems. Bevy 0.5 was "the one where we rewrote Bevy ECS". Bevy 0.6 was "the one where we rewrote Bevy Render". These massive reworks took time, and as a result held back a bunch of other useful features and bug fixes. They also created pressure to "crunch" and finish big features quickly to unblock releases. Crunching is unhealthy and should be avoided at all costs!
The Bevy Community has reached relative consensus that we should have a more regular, more predictable release schedule. One where large features can't gum up the system.
From now on, we will cut releases approximately once every three months (as an upper bound ... sometimes we might release early if it makes sense). After the end of a release cycle, we will start preparing to cut a release. If there are small tweaks that need to be made or "life happens" ... we will happily postpone releases. But we won't hold releases back for "big ticket" items anymore.
We are balancing a lot of different concerns here:
- Building trust with Bevy contributors that their changes will land in a timely manner
- Building trust with Bevy users that they will receive regular updates and bug fixes
- Giving enough time between releases to cut down on churn in the Bevy Plugin ecosystem (Bevy isn't "stable" yet, but longer releases give reasonable windows of "ecosystem stability")
- Providing enough content in a release to generate "hype". Bevy release blog posts tend to be a "rallying cry" for the community and I don't want to lose that.
- Establishing proper work / life balance for core developers (crunch is bad!)
We will refine this process over time and see what works best.
More Renderer Features #
- Post-Processing Stack / HDR / Bloom: HDR and bloom almost made it into Bevy 0.6, but we decided to hold them back so we can polish them a bit and build a proper "modular post-processing stack".
- Skeletal Animation: Ultimately Bevy will have a general purpose, property based animation system (we already have a working implementation). We've been holding off on adding skeletal animation, so we can slot it in to that system, but in retrospect that was a mistake. People need skeletal animation now. In the short term we will build a scoped 3d skeletal animation system, just to get the ball rolling. Then later we will port it to the general purpose system (whenever that is ready),
- Screen Space Ambient Occlusion (SSAO): A popular and straightforward ambient occlusion approximation that can drastically improve render quality.
- Global Illumination: GI will provide a massive boost to the feel of "realism", so it is worth prioritizing at least one form of GI in the short term. This is a complicated topic and will require experimentation.
- Compressed Textures: This will make scenes load faster and cut down on GPU memory usage.
- Shadow Filters and Cascades: Rob Swain (@superdump) has already done a lot of work in this area, so we will hopefully see that materialize in a Bevy release soon.
- PBR Shader Code Reuse: We will make it easier to define custom PBR shaders by making the PBR shader more modular and making it easier to import specific parts of the PBR shader.
UI Refresh #
We will break ground on the Bevy Editor this year. To do that, we need a number of improvements to Bevy UI:
- Improved "data driven UI" (potentially "reactive")
- A solid set of pre-constructed widgets
- Generally improved UX
We now have a plethora of UI experiments in the Bevy community. Over the next few months we will refine our scope and begin the process of "selecting a winner".
Asset Preprocessing #
Preprocessing assets is a critical part of a production game engine. It cuts down on startup times, reduces our CPU and GPU memory footprint, enables more complicated development workflows, makes it easier to ship assets with games, and cuts down on the final size of a deployed game. We've made it this far without an asset preprocessing system ... but barely. Solving this problem ASAP is a high priority for me.
Scene Improvements #
Nested scenes, property overrides, inline assets, and nicer syntax are all on the agenda. We already have a number of working experiments in these areas, so we should see relatively quick progress here.
The New Bevy Book #
The current Bevy Book is a great way to learn how to set up Bevy and dip your toes into writing Bevy Apps. But it barely scratches the surface of what Bevy can do.
To solve this problem @alice-i-cecile has started working on a new Bevy Book, with the goal of being a complete learning resource for Bevy. If you are interested in helping out, please reach out to them!
The Bevy Monthly Newsletter #
The Bevy Community is a vibrant and active place. Currently most community content is posted in the #showcase section of The Bevy Discord. The upcoming Monthly Bevy Newsletter will be a consolidated, shareable resource that we will post to places like Reddit and Twitter.
Support Bevy #
Sponsorships help make my full time work on Bevy sustainable. If you believe in Bevy's mission, consider sponsoring me (@cart) ... every bit helps!
Contributors #
A huge thanks to the 170 contributors that made this release (and associated docs) possible! In random order:
- @bilsen
- @jcornaz
- @Guvante
- @Weasy666
- @jakobhellermann
- @gfreezy
- @MichaelHills
- @tcmal
- @temhotaokeaha
- @nicopap
- @dimitribobkov
- @Newbytee
- @TheRawMeatball
- @marcospb19
- @MarenFayre
- @jleflang
- @piedoom
- @FlyingRatBull
- @thomasheartman
- @dburrows0
- @squidboylan
- @GarettCooper
- @nside
- @deprilula28
- @Jbat1Jumper
- @HackerFoo
- @MatheusRich
- @inodentry
- @cryscan
- @aleksator
- @Toqozz
- @concave-sphere
- @jesseviikari
- @dependabot
- @zicklag
- @mnett82
- @guimcaballero
- @lukors
- @alice-i-cecile
- @fintelia
- @BoxyUwU
- @gcoakes
- @folke
- @iwikal
- @tsoutsman
- @phrohdoh
- @julhe
- @Byteron
- @TehPers
- @andoco
- @djeedai
- @branan
- @follower
- @MiniaczQ
- @terrarier2111
- @joshuataylor
- @CleanCut
- @akiross
- @rukai
- @PaperCow
- @CGMossa
- @Josh015
- @gschup
- @james7132
- @MyIsaak
- @Hoidigan
- @mccludav
- @mnmaita
- @sapir
- @gilescope
- @VVishion
- @sarkahn
- @fractaloop
- @KDecay
- @aloucks
- @the-notable
- @mirkoRainer
- @Iaiao
- @hymm
- @jacobgardner
- @Protowalker
- @godsmith99x
- @Weibye
- @lberrymage
- @anchpop
- @willolisp
- @trolleyman
- @msklywenn
- @deontologician
- @johanhelsing
- @memoryruins
- @ahmedcharles
- @vabka
- @bytebuddha
- @louisgjohnson
- @r00ster91
- @parasyte
- @illuninocte
- @jihiggins
- @Dimev
- @szunami
- @tiagolam
- @payload
- @mrk-its
- @Ixentus
- @dintho
- @CptPotato
- @bjorn3
- @CAD97
- @lwansbrough
- @Ratysz
- @vgel
- @dixonwille
- @KirmesBude
- @Tobenaii
- @pbalcer
- @msvbg
- @Philipp-M
- @Waridley
- @StarArawn
- @ickk
- @IceSentry
- @Lythenas
- @Shatur
- @Grindv1k
- @aevyrie
- @wilk10
- @Davier
- @timClicks
- @DJMcNab
- @r4gus
- @rparrett
- @mfdorst
- @Veykril
- @thebluefish
- @forbjok
- @bytemuck
- @dbearden
- @OptimisticPeach
- @Weibye-Breach
- @MrGVSV
- @RichoDemus
- @R3DP1XL
- @jak6jak
- @blaind
- @YohDeadfall
- @cart
- @MinerSebas
- @CrazyRoka
- @NiklasEi
- @superdump
- @lassade
- @yetanothercheer
- @64kramsystem
- @mockersf
- @billyb2
- @molikto
- @mtsr
- @Abhuu
- @kumorig
- @yilinwei
- @Nilirad
- @SarthakSingh31
- @Frizi
- @dataphract
- @Sheepyhead
- @simensgreen
- @NathanSWard
- @remilauzier
- @fluffysquirrels
Full Change Log #
Added #
- New Renderer
- Clustered forward rendering
- Frustum culling
- Sprite Batching
- Materials and MaterialPlugin
- 2D Meshes and Materials
- WebGL2 support
- Pipeline Specialization, Shader Assets, and Shader Preprocessing
- Modular Rendering
- Directional light and shadow
- Directional light
- Use the infinite reverse right-handed perspective projection
- Implement and require
#[derive(Component)]on all component structs - Shader Imports. Decouple Mesh logic from PBR
- Add support for opaque, alpha mask, and alpha blend modes
- bevy_gltf: Load light names from gltf
- bevy_gltf: Add support for loading lights
- Spherical Area Lights
- Shader Processor: process imported shader
- Add support for not casting/receiving shadows
- Add support for configurable shadow map sizes
- Implement the
Overflow::Hiddenstyle property for UI - SystemState
- Add a method
iter_combinationson query to iterate over combinations of query results - Add FromReflect trait to convert dynamic types to concrete types
- More pipelined-rendering shader examples
- Configurable wgpu features/limits priority
- Cargo feature for bevy UI
- Spherical area lights example
- Implement ReflectValue serialization for Duration
- bevy_ui: register Overflow type
- Add Visibility component to UI
- Implement non-indexed mesh rendering
- add tracing spans for parallel executor and system overhead
- RemoveChildren command
- report shader processing errors in
RenderPipelineCache - enable Webgl2 optimisation in pbr under feature
- Implement Sub-App Labels
- Added
set_cursor_icon(...)toWindow - Support topologies other than TriangleList
- Add an example 'showcasing' using multiple windows
- Add an example to draw a rectangle
- Added set_scissor_rect to tracked render pass.
- Add RenderWorld to Extract step
- re-export ClearPassNode
- add default standard material in PbrBundle
- add methods to get reads and writes of Access
- Add despawn_children
- More Bevy ECS schedule spans
- Added transparency to window builder
- Add Gamepads resource
- Add support for #else for shader defs
- Implement iter() for mutable Queries
- add shadows in examples
- Added missing wgpu image render resources.
- Per-light toggleable shadow mapping
- Support nested shader defs
- use bytemuck crate instead of Byteable trait
iter_mut()for Assets type- EntityRenderCommand and PhaseItemRenderCommand
- add position to WindowDescriptor
- Add System Command apply and RenderGraph node spans
- Support for normal maps including from glTF models
- MSAA example
- Add MSAA to new renderer
- Add support for IndexFormat::Uint16
- Apply labels to wgpu resources for improved debugging/profiling
- Add tracing spans around render subapp and stages
- Add set_stencil_reference to TrackedRenderPass
- Add despawn_recursive to EntityMut
- Add trace_tracy feature for Tracy profiling
- Expose wgpu's StencilOperation with bevy
- add get_single variant
- Add builder methods to Transform
- add get_history function to Diagnostic
- Add convenience methods for checking a set of inputs
- Add error messages for the spooky insertions
- Add Deref implementation for ComputePipeline
- Derive thiserror::Error for HexColorError
- Spawn specific entities: spawn or insert operations, refactor spawn internals, world clearing
- Add ClearColor Resource to Pipelined Renderer
- remove_component for ReflectComponent
- Added ComputePipelineDescriptor
- Added StorageTextureAccess to the exposed wgpu API
- Add sprite atlases into the new renderer.
- Log adapter info on initialization
- Add feature flag to enable wasm for bevy_audio
- Allow Option<NonSend
> and Option<NonSendMut > as SystemParam - Added helpful adders for systemsets
- Derive Clone for Time
- Implement Clone for Fetches
- Implement IntoSystemDescriptor for SystemDescriptor
- implement DetectChanges for NonSendMut
- Log errors when loading textures from a gltf file
- expose texture/image conversions as From/TryFrom
- [ecs] implement is_empty for queries
- Add audio to ios example
- Example showing how to use AsyncComputeTaskPool and Tasks
- Expose set_changed() on ResMut and Mut
- Impl AsRef+AsMut for Res, ResMut, and Mut
- Add exit_on_esc_system to examples with window
- Implement rotation for Text2d
- Mesh vertex attributes for skinning and animation
- load zeroed UVs as fallback in gltf loader
- Implement direct mutable dereferencing
- add a span for frames
- Add an alias mouse position -> cursor position
- Adding
WorldQueryforWithBundle- Automatic System Spans
- Add system sets and run criteria example
- EnumVariantMeta derive
- Added TryFrom for VertexAttributeValues
- add render_to_texture example
- Added example of entity sorting by components
- calculate flat normals for mesh if missing
- Add animate shaders example
- examples on how to tests systems
- Add a UV sphere implementation
- Add additional vertex formats
- gltf-loader: support data url for images
- glTF: added color attribute support
- Add synonyms for transform relative vectors
Changed #
- Relicense Bevy under the dual MIT or Apache-2.0 license
- [ecs] Improve
Commandsperformance - Merge AppBuilder into App
- Use a special first depth slice for clustered forward rendering
- Add a separate ClearPass
- bevy_pbr2: Improve lighting units and documentation
- gltf loader: do not use the taskpool for only one task
- System Param Lifetime Split
- Optional
.system - Optional
.system(), part 2 - Optional
.system(), part 3 - Optional
.system(), part 4 (run criteria) - Optional
.system(), part 6 (chaining) - Make the
iter_combinatorsexamples prettier - Remove dead anchor.rs code
- gltf: load textures asynchronously using io task pool
- Use fully-qualified type names in Label derive.
- Remove Bytes, FromBytes, Labels, EntityLabels
- StorageType parameter removed from ComponentDescriptor::new_resource
- remove dead code: ShaderDefs derive
- Enable Msaa for webgl by default
- Renamed Entity::new to Entity::from_raw
- bevy::scene::Entity renamed to bevy::scene::DynamicEntity.
- make
sub_appreturn an&Appand addsub_app_mut() -> &mut App - use ogg by default instead of mp3
- enable
wasm-bindgenfeature on gilrs - Use EventWriter for gilrs_system
- Add some of the missing methods to
TrackedRenderPass - Only bevy_render depends directly on wgpu
- Update wgpu to 0.12 and naga to 0.8
- Improved bevymark: no bouncing offscreen and spawn waves from CLI
- Rename render UiSystem to RenderUiSystem
- Use updated window size in bevymark example
- Enable trace feature for subfeatures using it
- Schedule gilrs system before input systems
- Rename fixed timestep state and add a test
- Port bevy_ui to pipelined-rendering
- update wireframe rendering to new renderer
- Allow
Stringand&StringasIdforAssetServer.get_handle(id) - Ported WgpuOptions to new renderer
- Down with the system!
- Update dependencies
ronwinit& fixcargo-denylists - Improve contributors example quality
- Expose command encoders
- Made Time::time_since_startup return from last tick.
- Default image used in PipelinedSpriteBundle to be able to render without loading a texture
- make texture from sprite pipeline filterable
- iOS: replace cargo-lipo, and update for new macOS
- increase light intensity in pbr example
- Faster gltf loader
- Use crevice std140_size_static everywhere
- replace matrix swizzles in pbr shader with index accesses
- Disable default features from
bevy_assetandbevy_ecs - Update tracing-subscriber requirement from 0.2.22 to 0.3.1
- Update vendored Crevice to 0.8.0 + PR for arrays
- change texture atlas sprite indexing to usize
- Update derive(DynamicPlugin) to edition 2021
- Update to edition 2021 on master
- Add entity ID to expect() message
- Use RenderQueue in BufferVec
- removed unused RenderResourceId and SwapChainFrame
- Unique WorldId
- add_texture returns index to texture
- Update hexasphere requirement from 4.0.0 to 5.0.0
- enable change detection for hierarchy maintenance
- Make events reuse buffers
- Replace
.insert_resource(T::default())calls withinit_resource::<T>() - Improve many sprites example
- Update glam requirement from 0.17.3 to 0.18.0
- update ndk-glue to 0.4
- Remove Need for Sprite Size Sync System
- Pipelined separate shadow vertex shader
- Sub app label changes
- Use Explicit Names for Flex Direction
- Make default near plane more sensible at 0.1
- Reduce visibility of various types and fields
- Cleanup FromResources
- Better error message for unsupported shader features Fixes #869
- Change definition of
ScheduleRunnerPlugin - Re-implement Automatic Sprite Sizing
- Remove with bundle filter
- Remove bevy_dynamic_plugin as a default
- Port bevy_gltf to pipelined-rendering
- Bump notify to 5.0.0-pre.11
- Add 's (state) lifetime to
Fetch - move bevy_core_pipeline to its own plugin
- Refactor ECS to reduce the dependency on a 1-to-1 mapping between components and real rust types
- Inline world get
- Dedupe move logic in remove_bundle and remove_bundle_intersection
- remove .system from pipelined code
- Scale normal bias by texel size
- Make Remove Command's fields public
- bevy_utils: Re-introduce
with_capacity(). - Update rodio requirement from 0.13 to 0.14
- Optimize Events::extend and impl std::iter::Extend
- Bump winit to 0.25
- Improve legibility of RunOnce::run_unsafe param
- Update gltf requirement from 0.15.2 to 0.16.0
- Move to smallvec v1.6
- Update rectangle-pack requirement from 0.3 to 0.4
- Make Commands public?
- Monomorphize vrious things
- Detect camera projection changes
- support assets of any size
- Separate Query filter access from fetch access during initial evaluation
- Provide better error message when missing a render backend
- par_for_each: split batces when iterating on a sparse query
- Allow deriving
SystemParamon private types - Angle bracket annotated types to support generics
- More detailed errors when resource not found
- Moved events to ECS
- Use a sorted Map for vertex buffer attributes
- Error message improvements for shader compilation/gltf loading
- Rename Light => PointLight and remove unused properties
- Override size_hint for all Iterators and add ExactSizeIterator where applicable
- Change breakout to use fixed timestamp
Fixed #
- Fix shadows for non-TriangleLists
- Fix error message for the
Componentmacro'scomponentstorageattribute. - do not add plugin ExtractComponentPlugin twice for StandardMaterial
- load spirv using correct API
- fix shader compilation error reporting for non-wgsl shaders
- bevy_ui: Check clip when handling interactions
- crevice derive macro: fix path to render_resource when importing from bevy
- fix parenting of scenes
- Do not panic on failed setting of GameOver state in AlienCakeAddict
- Fix minimization crash because of cluster updates.
- Fix custom mesh pipelines
- Fix hierarchy example panic
- Fix double drop in BlobVec::replace_unchecked (#2597)
- Remove vestigial derives
- Fix crash with disabled winit
- Fix clustering for orthographic projections
- Run a clear pass on Windows without any Views
- Remove some superfluous unsafe code
- clearpass: also clear views without depth (2d)
- Check for NaN in
Camera::world_to_screen() - Fix sprite hot reloading in new renderer
- Fix path used by macro not considering that we can use a sub-crate
- Fix torus normals
- enable alpha mode for textures materials that are transparent
- fix calls to as_rgba_linear
- Fix shadow logic
- fix: as_rgba_linear used wrong variant
- Fix MIME type support for glTF buffer Data URIs
- Remove wasm audio feature flag for 2021
- use correct size of pixel instead of 4
- Fix custom_shader_pipelined example shader
- Fix scale factor for cursor position
- fix window resize after wgpu 0.11 upgrade
- Fix unsound lifetime annotation on
Query::get_component - Remove double Events::update in bevy-gilrs
- Fix bevy_ecs::schedule::executor_parallel::system span management
- Avoid some format! into immediate format!
- Fix panic on is_resource_* calls (#2828)
- Fix window size change panic
- fix
Defaultimplementation ofImageso that size and data match - Fix scale_factor_override in the winit backend
- Fix breakout example scoreboard
- Fix Option<NonSend
> and Option<NonSendMut > - fix missing paths in ECS SystemParam derive macro v2
- Add missing bytemuck feature
- Update EntityMut's location in push_children() and insert_children()
- Fixed issue with how texture arrays were uploaded with write_texture.
- Don't update when suspended to avoid GPU use on iOS.
- update archetypes for run criterias
- Fix AssetServer::get_asset_loader deadlock
- Fix unsetting RenderLayers bit in without fn
- Fix view vector in pbr frag to work in ortho
- Fixes Timer Precision Error Causing Panic
- [assets] Fix
AssetServer::get_handle_path- Fix bad bounds for NonSend SystemParams
- Add minimum sizes to textures to prevent crash
- [assets] set LoadState properly and more testing!
- [assets] properly set
LoadStatewith invalid asset extension- Fix Bevy crashing if no audio device is found
- Fixes dropping empty BlobVec
- [assets] fix Assets being set as 'changed' each frame
- drop overwritten component data on double insert
- Despawn with children doesn't need to remove entities from parents children when parents are also removed
- reduce tricky unsafety and simplify table structure
- Use bevy_reflect as path in case of no direct references
- Fix Events::<drain/clear> bug
- small ecs cleanup and remove_bundle drop bugfix
- Fix PBR regression for unlit materials
- prevent memory leak when dropping ParallelSystemContainer
- fix diagnostic length for asset count
- Fixes incorrect
PipelineCompiler::compile_pipeline()step_mode- Asset re-loading while it's being deleted
- Bevy derives handling generics in impl definitions.
- Fix unsoundness in
Query::for_each_mut- Fix mesh with no vertex attributes causing panic
- Fix alien_cake_addict: cake should not be at height of player's location
- fix memory size for PointLightBundle
- Fix unsoundness in query component access
- fixing compilation error on macos aarch64
- Fix SystemParam handling of Commands
- Fix IcoSphere UV coordinates
- fix 'attempted to subtract with overflow' for State::inactives